ひきつづきAlveo U50を動かすお話です。以前、FixstarsさんのところでU50のXDMAを動かした記事 を拝見して、同じように UltraRAM を接続して Core i3-6100 + DDR4-2133 Dual channelで動かしてみたら、こんな感じでした。
Write Performance
Fixstars さんの POWER8 なホストでは 12GB/s とか出ているので、この差は CPU パワーだったりメモリシステムだったりするのでしょうか。単に DMA 転送しているだけだと CPU 使用率がスカスカで、すぐクロックが下がって DMA まで遅くなってしまうので、裏で yes > /dev/null してクロック周波数を維持しています (本当はちゃんとクロック周波数のコントロールを設定すればいいのですが。)
それで、HBM を XDMA に接続するのはなんとなくめんどくさそうで二の足を踏んでいたのですが、そろそろ本気出さないといけない感じになってきましたので、とりあえずやってみることにしました。方針としては、
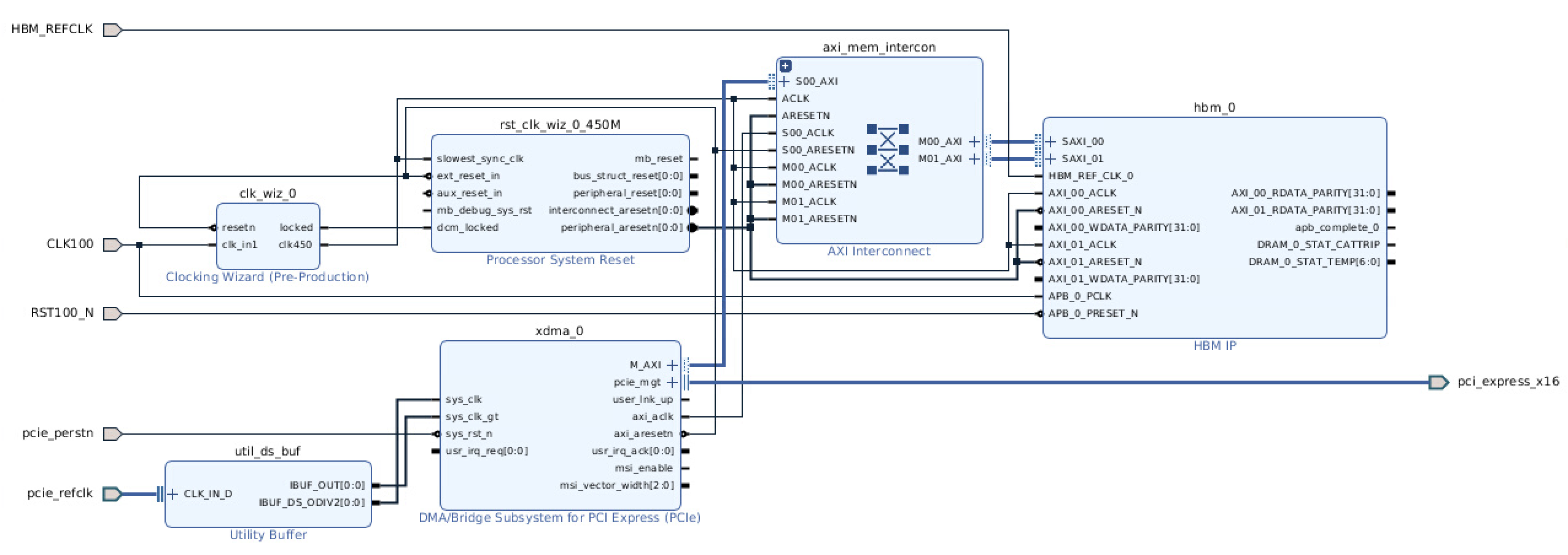
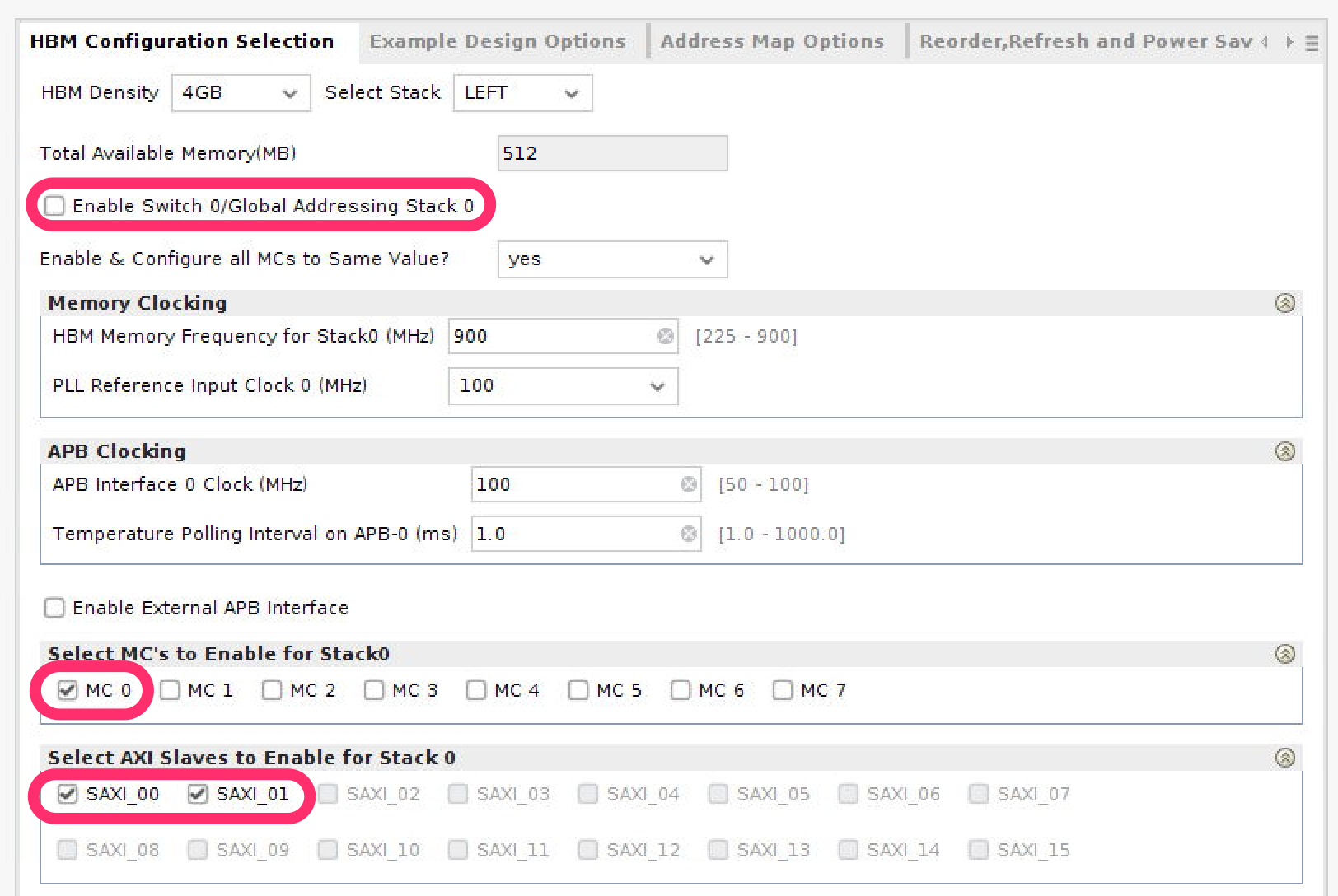
あとで並列アクセスをする気がするので、とりあえず HBM IP コアの global addressing の機能はつかわない とりあえず 1ch、512MB だけ動かす HBM reference clock (100MHz) は SYSCLK3 (BC18, BB18) から それ以外のクロックは SYSCLK2 (G16, G17) と、それで駆動する MMCM から HBM IP の AXI インタフェイスは MMCM で 450MHz を作ってそれで駆動 ということにしました。いろいろと紆余曲折があって、今日も半日くらい使ったのですが、ブロックデザイン全体・HBM IP のチャネルの設定・アドレスマップは以下のようになっています。
CLK100 とか RST100_N はブロックデザインの外側の RTL で、CMC_CLK から作っています。アドレスマップをみると unmapped slaves があるので、あれ、と思う方もいらっしゃるかもしれませんが、global addressing を切ってしまうと、8つあるメモリチャネル (512MB) を半分ずつにした 256MB の (pseudo channel に対応した) 領域が 16あるAXIインタフェイスと1:1の関係になるようで、SAXI_00 だけでは正しく動作しませんでした。転送速度を UltraRAM のときと同じように測定すると、
Write Performance
ということで、ひとまずバンド幅はちゃんと出ているようですが、AXI Interconnect を性能側に振った設定にして、出力の register slice などを on にしないとタイミングが meet しなかったので、左右両スタックの HBM をこのまま 16ch + 16ch で AXI interconnect に直結するのはちょっと性能的に厳しそうで (AXI interconnect のポート数の制約もあるし) 、やはり global addressing を利用するのが賢いのかなあ、という気がしています。