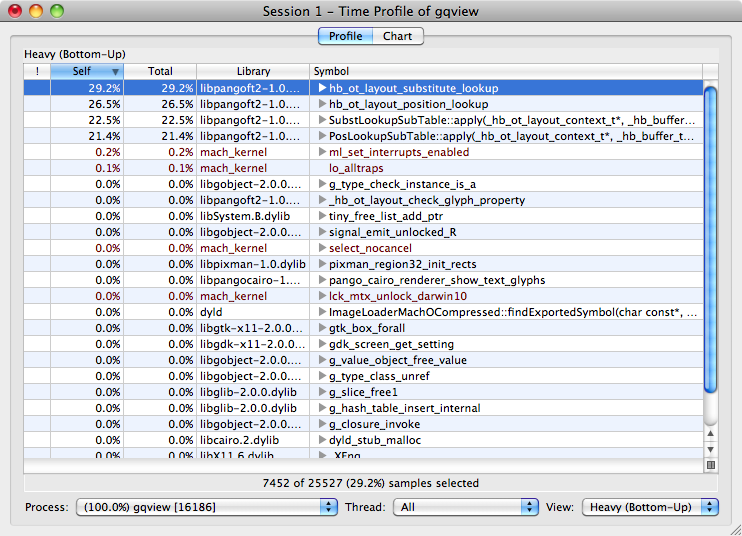
Testing the latest GTK+-X11 (installed by MacPorts) on my MacBook, but opening particular windows take too long… I found this problem with my own application, but this is common to other GTK-based applications.
Last night I took a profile with GQVIEW, then found the most time consuming part is Pango. But… why?
月: 2009年9月
Nuke curbs
UN council endorses nuclear curbs.
If we have guns, we’ll fire someday.
If we don’t have, we’ll not fire.
We decided to choose the “option 2”.
It’s a memorial moment of humankind (in many aspects…).
BTW, what about the case we’re fired upon?
That’s what we’re asked now.
31
小学校の同級生とばったり、電車の中で会った。
まあ、お互いずっと地元に住んでいるから、会っても不思議じゃないのだけれど。
いま南青山でフロリレージュというフレンチレストランをやっているのだそうだ。ちょっと調べたら、Hanako にも記事が出ていたりして、かなり人気が出ている模様。
いま振り返れば、彼は小学生の時から「僕はレストランをやるんだ!」と言っていて、それを貫き通したんだな、と思う。並大抵の意志では掴み取ることのできない夢だと思う。すごいな。
僕らも、いよいよ31歳です。
僕はちゃんと、なりたかった大人になれてるのかな。
そうそう、同い年の人がやっているお店といえば、京都烏丸御池の「あさきぬ」。こちらは、フレンチほど敷居が高くなくて、僕でも気軽に入れます。
最近の自転車
土曜と月曜と。
土曜はへろへろの状態で大学行って、帰りは調子よかったので環八を飛ばして、遠回りして世田谷通りを回って帰宅。
月曜はぶっちぎりの状態で大学行って、国立でグレナデンソーダ飲んで、帰ってきた。吉祥寺から国立までは五日市街道を玉川上水ぞいに 45 分くらい。真っ暗であんまり飛ばせなかったからなので、昼間ならもっと速いかもな。帰りは甲州街道で、調布まで35分。
二日あわせて 67.39km @ 25.1km/h (2h40m50s) odo 7103.7km
RECONF: Sep.18, 2009 at Utsunomiya U.
ホテルが駅からめちゃめちゃ遠かったため、激しく遅刻。
到着したら、最初のセッションの最後の発表でした。
[ 小容量FPGAによるスケーラブルなシステム評価環境の構築手法 ]
M-Coreアーキテクチャ (すごくたくさんの manycore) を実装するためのプラットフォーム。小さい FPGA をたくさん使うことで、メモリポート数を稼いだり、いろいろ。
ScalableCore unit / board という2種類のボードを組み合わせて mesh 状のシステムを構成する。
100 core をシミュレーションするには100枚のボードが必要? (児玉さん) → いまのところ 1 core / 1 board がシンプルなのでそうしているが、今後検討したい。
configuration とか、メモリへの書き込みはどうしているのか (ふんがさん) → configuration はひとつずつ PROM に書いている。メモリは BlockRAM に初期値を書いたり、次のバージョンでは SD カードから読み込める。
たのしそう…
[ An FPGA-based Tiny Processing System for Small Embedded System and Education ]
TinyCPU: Verilog で 200-300 行くらい。
レジスタは持っていない。完全にスタックアーキテクチャ (逆ポーランド記法で書けばなんでもできるので、コンパイラが簡単に作れる)。
やっぱり授業は大変らしい。
[ メニーコアSoC用形状適応型ネットワークオンチップの検討 ]
256 nodes で Crossbar-Torus 混成網とか。上位が torus で、下を mesh とかにする。
16 cores の中と外をつなぐところはどうなっている? crossbar なら 16+4 (東西南北) で 20×20? (吉瀨先生) → どうやらちがうらしい。外に出るところは MUX/DEMUX があるのか…
mesh mode と crossbar mode があるらしい。crossbar mode だとびゅーっと速く通過できる。局所性を利用するというよりは、低電力な mesh (バケツリレーしないといけない) で性能が足りなくなったら、crossbar (通過できる) に切り替えて高速に動かそうということだそうだ。
[ ネットワークテストベッドGtrcNET-10p3におけるパケットキャプチャおよびルータ機能の実装 ]
バンド幅や遅延をかえて、ネットワークシステムの性能評価をするためのシステム。あるいは、高精度なバンド幅測定やプロトコルのデバッグをすることもできる。
10GbE を XC2VP100 に soft core で実装。まじか。
DDR-SDRAM を 166MHz 裏表で動かすのは大変だそうです。
キャプチャフォワード:
実質的にサイズ無制限のキャプチャがほしいが、目的によってはペイロードは保存しなくてもよく、ヘッダ部分だけあればよい。3 ポートあれば、2ポートの間のヘッダだけを抽出して残りの1ポートから外に出せる。
関連研究の紹介:
NetFPGA, BEE3 など。
データのサイズが大きくなさそうなので、SRAM のほうがよさそうですがどうでしょう (吉瀨先生) → 遅延を入れたりすることを考えると、パケットをためておく必要があるので、充分なサイズが必要。1GB くらい。
[ 再構成デバイスMPLDの高密度実装に適した構成手法 ]
弘中研の学生さん。
メモリにもなる LUT を使った PLD. 高密度に実装できるところがポイント。
配置配線ツールとかもちゃんとある。
チップはフルカスタムで作った? (ふんがさん) → ほぼ手作りです。でも、規模が大きくなりすぎて検証できなくて、ちゃんと動かなかった。アナログ設計なので、nanosim なんかでシミュレーションしても不定値になるところがわからなかったりする。
[ LEDR/4相2線プロトコルコンバータを用いた非同期FPGAの構成 ]
FPGA はレジスタが多いので、クロック分配が大変 (電力食うし) 。じゃあ非同期にしましょう、というお話。
4相2線は小面積なので、演算器に向いており(FPGAはビット幅が自由なので、束データ方式は使いづらい)、LEDR (Level-Encoded Dual-Rail: 2相2線方式の一種) は長い配線に向いている (4相2線はデータ間にスペーサが必要だが、LEDRなら不要。ただし、回路的には面倒) 。
プロトコルコンバータをいれればいろいろ作れるんだな。かっこいい。
4相2線の場合はスペーサになるときに、すべてのロジックが 0 になったことを確認しないと、過渡的にへんな信号が出ることがあるので、気をつけてください (名古屋先生)
Switch block や connection block 間の配線のすべてのトラックは data x 2 + ack の3本のセットになる? つまり普通の FPGA の3倍配線が必要? (渡辺先生@岡山大) → はい。
[ レンズ結像系を用いない4コンテキストプログラマブル光再構成型ゲートアレイ用ライター ]
渡辺先生@静岡大の学生さん。
レンズを使わないで、反射型ホログラムとレーザーだけでいけるものを検討中。レンズで位置を補正できないので、回路構成情報に位置補正情報を埋め込んでしまう。
横から出す方のレーザーは位置あわせが必要? ビーム径は?(弘中先生) → SPD のサイズをあまり小さくすると感度 (というか応答時間) が下がるので、それをカバーできるくらいのものを考えている。パッケージの組み立て精度は充分に出るという前提で、パッケージをライターに入れたときは精度が怪しいから、そこを補正しようということを考えている。
[ FPGAによるHPCのためのストリーム計算に関する一検討 ~ 2次元ヤコビ法のためのスケーラブルパイプラインモジュールの設計と評価 ~ ]
Many core とかではメモリのバンド幅がボトルネック。FFTなんかはまだマシだが、計算密度が低いステンシル計算などではピーク性能の半分もでない。ものすごく長いパイプラインを作ってストリーム処理すればいい? でも、そんな都合よくいくかしら。
ステンシル計算なら、平面上の4近傍を見て計算してそれを次のタイムステップで使って・・・というところで計算密度が稼げる。
データストリームの場所場所で必要なバンド幅は異なる。しんどいところにデバイス境界がこないようにしないといけない。そうだよなあ… ここの設計手法が鍵になる気がする。
どれくらいのバンド幅が出ればいいのか、いまので充分なのか (中條先生) → 5GB/sec くらいは実現可能。メモリより太いチップ間の転送バンド幅があればいい。
2次元ヤコビ法ではうまくいきそうだけど、一般化して GPU に勝つ方向ではがんばれる? マルチチップの設計環境とかメモリの抽象化とかができるといいなあ (ふんがさん) → GPU は scale できない気がするので、性能的には勝てるかも。
[ 高精度浮動小数点演算用リコンフィギャラブルアクセラレータに用いる数学関数の実装手法に関する検討 ]
8倍長精度のアクセラレータ HP-DSFP を提案。
CORDICを使いたいけど、ビットシフトができない。ざんねん。多項式近似するぜ。
三角関数の計算には数千クロックかかるのか。むー。
8倍精度はやりすぎな気もしますが、こういうのがあってもいいね。
[ An FPGA-based Architecture for Verifying Collatz Conjecture ]
コラッツ予想: 偶数のときその数を2で割り、奇数の時3倍して1を加えると、任意の正の数が1になる。でも証明はされていない。
僕、昔それをやってたんですけど知ってますか (市川先生) → どーん。
こういう問題は、相手が無限大だからなあ。。。
RECONF: Sep.17, 2009 at Utsunomiya U.
[ FPGA を用いた回転パターンの実時間検出 ]
丸山研のひと。
FFTとかをして比較するのではなくて、回転・拡大縮小されたパターン画像との直接比較を考える。今回は拡大縮小は考えない模様。
相互相関関数をいっぱい計算するので、そこの計算量を頑張って減らしている。
VGA で 410fps, Full HD で 61fps.
– 理論的に誤差がどう、ということより、「検出できればよい」という方向だとどうか。回転の刻み角を減らしたりとか?
– ゆがみの検出とかにも適応できる? → このやり方ではむり
– 回路のうちデータを保持しておくところが大きいと思うけど、回路量のうちメモリの占める割合は? → 全部 LUT 内部でやっており、メモリは使っていない。
[ ロジックエレメントを節約したFPGAラベリング ]
ラベリング: 2値画像の連結成分の、島ごとにユニークな ID を割り当てる。
1 clock / pixel で FPGA に入力するとする。FPGA 内部に保持するのは数行分で、全部のデータを待たずに出力する。ただし、これだと数行掘り下げたときに島がくっつくかもしれないので、入力画像について制約をかける必要はある。
ある程度離れたところでつながっているものについてはあきらめちゃう、ということだが、実アプリで 20-concave というのはどうなのか (堀先生) → スキャンした文字とかだと、わりとこれでもいいかな、という感じ。
うずまきキャンディとか櫛みたいなものがベンチマークの絵で出てくると思うけど、どうでしょう (丸山先生) → 20pixel に入れば… デジタルカメラとかで、コストをかけずに何かの前処理としてラベリングができればいいかな (つまり、ラベリングがメインではないアプリケーションへの適用) と思っている。
[ FPGAアレイCubeを用いたレーベンシュタイン距離計算の性能評価 ]
よしみさんの発表。なんか元気そうで、何よりです。
Cube: XC3S4000 の一次元接続。
8×8 の短い部分文字列についてスコアを計算するモジュールをひとつの FPGA に 16 個。
CellとかGPUと比較。
パイプライン稼働率は 20% くらい。電力効率は 10〜100倍くらい。
パイプライン効率があまり上がらないのはなぜ (中條先生) → 100%出るのが対角線のときだけなので… たくさんデータセットをなげればいい。
データセットのサイズに上限はあるのか (児玉さん@AIST) → 上限はないのだが、いくつかに分割して実行しなければいけなくなる。配列長に対して実行時間の増加は linear.
[ FPGA による電源電圧制御回路の実装および制御精度の評価 ]
そえじーの発表。
ディジタル制御な DC-DC コンバータによる、データセンタとかでの DC 給電が目標。
FPGA で PID 制御をする。DC-DC converter にはどれくらい演算精度が必要か、とか。
100MHz のクロックの位相をずらして 400MHz 相当の時間分解能を手に入れた!
演算自体は4クロックで終わる。
アナログ制御の DC/DC と較べるとどうかは評価しているか (児玉さん@AIST) → PID とかよりもっと難しい (アナログではできない) 制御をやる予定なので、デジタル前提です。
いいね。
[ 配線性を利用する低消費電力指向のクラスタリング及び配置手法 ]
クラスタ外の配線をなるべくクラスタ内に取り込む方向でがんばる。
LB 間の配線数を気にしながら集めていく。
消費電力が改善したのにクリティカルパス遅延が悪化したのはなぜか。どういう状況 (谷川先生) → クラスタ段数が増えちゃうところがあるから?
配置配線にかかる時間は遅くなっているのか (ふんがさん) → あまり変わりません。
[ 実装効率改善へ向けたP同値類に基づくLUTの論理出現率に関する調査 ]
FPGAは柔軟だけど、回路によっては使われない論理ブロックがあったりもする。
でも、完全な論理表現能力がなくてもいいじゃない?
P同値類: (3入力以上とかで) 入力の順番を入れ替えると同じ関数になるもの。
これを使うと、論理関数表現から P-representative 表現にすることで、
3入力: 256 pattern / 8bit → 80 pattern / 7bit
4入力: 64k pattern / 16bit → 3,984 pattern / 12bit
のように必要なメモリ量を縮約できる。
一方でマルチプレクサや配線領域が増加することが問題。
論理関数の使用時における偏りを利用できないか?
MCNC benchmark を 117 種類、2つの異なるテクノロジマッピング手法を用いて評価。
最大105種類のP同値類。35% くらいの論理関数が P 同値類をもつ。
なかなかおもしろい。
k が大きくなるとより有効そう (弘中先生) → がんばります
6入力だけど6入力全部使わないものとかもあるわけで、そういうのをもう少し細かく分けてみたらもっといいかもしれない (児玉さん)
[ 電力を再構成可能なFlex Power FPGAチップの設計と試作 ]
Flex power FPGA の新チップ。動いてる。しかも CAD も!!
チップは 90nm.
設計はどうやっている? (ふんがさん) → 自動配置配線はまったく使っていません (!!!)
チップ製造後のテストはどうやりました? (飯田先生) → 業者に出してテストもしたけど、自分たちでやったのと違う…
製造前の見積もりと現実の違いは? (谷川先生) → 1/10 くらいになるはずだったけど、半分くらいになってしまった。速いトランジスタだと Vth 変更の効きが悪いとか、いろいろあるけどこれから検討。
動くことは確認できたわけだが、集積度が普通の FPGA に負けないこともポイントだと思う。そのへんはどうか (児玉さん) → やっぱり overhead は大きいかも…
[ Dual-Vthセルの利用による動的リコンフィギャラブルプロセッサのリーク電力削減の評価 ]
[ YAWARA: 自己最適化計算機システム・プロジェクト ]
実行前最適化処理 (コンパイラとか) の限界。複数のプログラムの同時実行や、入力データによる挙動の変化をカバーすることができない。
ユーザ透過な形で動的な最適化をすることができないか?
メタレベル計算原理に基づく柔構造計算機: プログラムの実行と並行してその挙動を把握し、その履歴に基づいて将来を予測して計算機を造り替える能力をもつ計算機。
最初は FPGA とかでやろうと思っていたが、VLIW でたくさんスレッドを走らせる方向に行っている、とのこと。それが正解だと思う。
しかし、こういうのは意外と楽しそうで、発表を聴けてよかった。
Proxy problem with Microsoft Update
Today I had 20+ PCs to run Microsoft Update 🙁
I’ve found that one of them can’t download any update modules (while it can show the list of updates). This is because winhttp’s proxy configuration (it’s separated from wininet’s proxy configuration that we can manage from the “Internet Options” dialog) was broken.
There’s no GUI to configure winhttp’s proxy setting, but “proxycfg” command does… and I have done.
Strange strange Windows…
Maintenance
Movable Type をやっと新しくしました。
うごけー。
H2B
打ち上げ成功おめでとうございます。
無事に ISS にドッキングしてくれるまでは、気が抜けないんでしょうけれど。
実は友人が HTV の設計に携わってました。
自分が作ったものが宇宙にいく、というのはどんな感じなんだろうなあ。
いいね。
今日の自転車
今日はちょこっとトレーニングしてから出勤。
15km 全力で走り、15km 適当に走って大学。帰りは 10km。
最初の 15km はいつもの多摩川で、視界に入ったロードレーサーはいつもどおり、全部追い抜いた。
調子はまあまあだと思うが、乗ったあとときどき膝が痛むので、しばらく慎重にいこうと思う。
37min17s, HR average 165, peak 193, T/E 4.5
57min21s, HR average 155, peak 187, T/E 3.7
50.72km @ 27.3km/h (1h51m07s) odo 7036.3km