I had wrote a Linux driver for our FPGA + PCI Express board, and recently ported it to FreeBSD. While there are many documentation for Linux device driver (i.e, LDD3), I could find (almost) no comprehensive document about writing FreeBSD driver.
[ open/close/read/write/seek ]
read() and write() are mostly done by uio_move(). See uio (9) for detail.
Basically we don’t have to implement seek(). uio structure has a pointer to seek.
[ mmap ]
FreeBSD’s mmap implementation is really BEAUTIFUL. Just modify “vm_addr_t *paddr” to return corresponding physical address.
[ DMA layer ]
bus_dma (9) framework provides sophisticated DMA framework. I’ve read /usr/src/sys/dev/hifn/hifn7751.c as my reference.
Happy hacking!
月: 2010年5月
きょうのじてんしゃ
明日から天気が崩れそうだったので、夜中にすこしマジメに乗って帰宅。
43.64km @ 25.8km/h (1h41m26s) odo 8561.4km
きょうのじてんしゃ
家を出ようとしたら、リアがパンクしてた。
どうも、リムホールのところでチューブがダメになるっぽい。
リムフラップはちゃんとしてるんだが、軽量チューブだと弱いのかな?
そういうわけで、今日からリアは普通のチューブ。
スプロケットは久々に 11-23T に戻りました。ぐいぐい走るぜ!
22.56km @ 23.3km/h (57m56s) odo 8517.5km
MacBook
MacBook late 2008 に 750GB のディスクを載せました。
これで研究関係のデータを詰め込めます。最強です。

全日空旧塗装機
ときどき見かけてたのですが、
伊丹で目撃しました。今回は時間があって、写真が撮れましたよ。


RECONF研 (May.14, 2010)
[FPGAを用いた様々な大きさ、回転角を持つパターンの検出手法の検討]
梶原さん: 回転のところで、隣のピクセルに移動しちゃったところだけを計算して処理量を減らしているんだけど、大きな画像になるとあまり節約にならないのでは?
鈴木さん: いま使っているFPGAでできるサイズの画像ではこれでよいと思っている。大きいのでは違うけれど。
[振動抑制を考慮した追従システムのFPGAによる実装]
現代制御なアルゴリズムをMATLAB/Simulink のモデルから実装。
組み込みなソフトウェアに対してどれくらいのアドバンテージがあるか?
Xilinx, Altera などのツールはあるけど、主に DSP 用であり、FPGA 用の機種依存なブロックを使ってやらないといけない。Mathworks が出しているツールは限定的だが標準のブロックをサポートしている。
制震制御: たとえば水の入ったコップを、水をこぼさずに高速に移動する。
鋳造のラインとかで使う。装置の制約 (最大速度、最大加速度など) を満たすために、リアルタイムでシミュレーションしながら次の動作を決める (予測制御) 必要があり、計算が大変で、Atom Z530 では実時間制御に間に合わない!
ソフトウェア実行版とHDL版ではMATLABのレベルで書き方を変えないとダメ。
京さん: 組み込みで速いプロセッサを使えないのはなぜ?
市川先生: コストとか、あるいは他機種と共通部品だったりするので。高速な予測制御はソフトウェアではできないので、コストが許すならばFPGAなどを導入することで、いままでできなかったことができるようになる。今回は、ふつうの市販のツールでどれくらいのものができるかに興味があった。
[SIMD型並列度可変プロセッサコアの提案とその検証]
Super H-2互換ソフトIP の Aquarius (available at opencores.org) の Verilog 記述を使用。
マルチコアにするよりはSIMDのほうが省面積な感じで、SIMD のほうが、使用 LUT に比例して素直に性能が伸びる。
柴田先生: 演算器とレジスタはセットにして並べるの?
田邊さん: はい。
柴田先生: 開発環境はどうしていますか?
田邊さん: SSE用の開発環境とかの出力を translate することを考えています。
渡邊先生: オリジナルの命令セットに対してどういったSIMD命令を追加していますか?
田邊さん: 実は命令は追加していなくて、すべての演算器が同じ命令を実行するようになっている。演算ユニット間のネットワークができてから、通信関係のことを考えたい。
[PC-FPGA複合クラスタにおけるソフトウェア-ハードウェア間通信と遠隔呼び出し]
PCクラスタ用ネットワークにおけるFPGAの利用はMaestro2 (筑波大) とか DIMMnet (慶應)とかに見られるし、計算にも使われている。
井口先生: なんか遅いのは、実は測定タイマの関数の精度の問題では?もっといい性能が出ているかも :p
小畑先生: そうかもしれません 🙂
梶原さん: FPGA から PC を呼ぶ、という処理ができるようになっているけど、どう使う?対称性があるのはいいけれど。
小畑先生: ちょっと検討します。
[複数FPGA上で動作するスケーラブルアレイプロセッサのためのGALS設計]
ステンシル計算とかをするための、globally async, locally sync なシステム。
FPGA ボードを複数使って検証。ストールの解決メカニズムがキモで、かなりうまくいっている。
小栗先生: dual port FIFO を使うとデータはうまくいくんだけど、handshake のところはむずかしいので、気をつけて作らないとmetastableに落ちて誤動作が起きることがあるので、複数のクロックを使うと難しいかも。
そうか・・・難しいなあ。
[複数の異なるアプリケーションを用いたFPGAベース・リコンフィギュラブルシステム用OSの性能評価]
ホスト PC にくっついた FPGA なんかで、複数の SW task が動くのは当然として、それに対応する複数の HW task を動かせるような OS 的なシステムを作っている。プロトタイプは SPARTAN3 を4つ搭載。
渡邊先生: HW task は1アプリケーションでFPGAひとつ?
児島先生: 再構成の事情とかでそうなっていますが、将来は何とかしたい。
[An Efficient Implementation of Exhaustive Verification of the Collatz Conjecture using DSP48E blocks of Xilinx Virtex-5 FPGAs]
専門委員会があって遅刻しましたごめんなさい。
市川先生と小栗先生がこれって何で証明できないのか、という議論で盛り上がる。
Virtex-II のときからの性能向上には DSP block の寄与が大きいとのこと。
[マルチFPGAプラットフォームFLOPS-2Dにおける演算パイプラインの実装]
ちょっと導入のスライドがまずかったなー。preliminary work だっていうのを前面に出さないと誤解される、ということがよくわかった。やってる内容は悪くないと思う。
[動的再構成デバイスによるリアルタイム翻訳システムの構築と検証]
DAP/DNA2!
納豆mics
納豆菌ゲノムのことについて、今朝の新聞 数紙に記事が載ったようですが、なんか、応用のほうに記事の興味が行っちゃっていて、あまりサイエンスでないので、ちゃんと書いておこうと思います。さまざまな応用について、とか、ねばねば生成のメカニズムそのものの解明は僕らの研究成果ではないので、それが僕らの成果であるように書かれちゃうと、なんだか他の人の成果を横取りしたみたいで若干申し訳ないしね。
さて、僕らのチームは納豆菌のゲノムを読みました。それの何がsignificantだったのか、ということをまとめておきます。
まず、プロジェクトの体制について。
納豆菌から DNA を抽出したりとか、シークエンサー (配列を細切れにして読み取る機械) を走らせたり、というところは、専門の方のご支援をいただきましたが、論文の著者リストを見ればわかる通り、基本的にこのプロジェクトは非常に少人数です。
基本的に実験室での作業は、大学院生の西藤さんという方が4年生から修士1年の春にかけて、ひとりでやりました。本人は、「いやー、たいしたことないですよー」とのことですが、これはいわゆる、優秀かつ謙虚な人というやつです (笑)。彼女が、データ解析も含めてかなりのところまでやって、最終的に配列をつないで遺伝子予測をして、というところから僕がお手伝いしました。ま、僕がいろいろ苦労した点もありますが、基本的には西藤さんが頑張った成果で、1.5 人くらいでやった感じです。
それで、2年弱、実質半年から1年くらいの時間で、全部が終わりました。これは、いわゆる次世代シークエンサーと呼ばれる装置と、さまざまな優秀なソフトウェアとコンピュータのおかげですが。
もっとも、納豆菌はすぐ近縁に、すでにゲノムが解読されている枯草菌という菌があるので、それが大いに参考になった、ということもありますが、少人数で短期間でゲノムが解読できるんだよ、といういい例になったのではないかと思います。
もうひとつは生物学的なこと。
生物学的な発見もいくつかありますが、ひとつ面白いのは、納豆菌が変質して糸を引かなくなるメカニズムが、ゲノム全体の解析で非常に強力に働いていることが明らかになったことです。
以前から、納豆菌にはトランスポゾンと呼ばれる、染色体上を飛び回る遺伝子 (!) が多く見られて、それがねばねば生成に関連するところに飛び込んで遺伝子を壊してしまい、結果として糸を引かなくなる、ということが言われてきており、納豆菌特有のトランスポゾンに関する論文も複数のグループから出ています。
僕らの解析の結果、さらに多くのトランスポゾンが見つかり、しかもわりと頻繁に動いているようだ、ということがわかりました。普通、こういう菌は産業的にも研究的にも、安定しないのであまり使われないのですが、これが連綿と食べられている国、というのはなかなかすごいかもしれません (笑)。
それで、納豆って身体にいいんですか?とか、ナットウキナーゼのこととか、いろいろ僕にきかれるのですが、そのあたりは専門家でないので、正直よくわかりません。だって、僕、基本的には計算機屋ですし。でも、納豆は好きですよ。
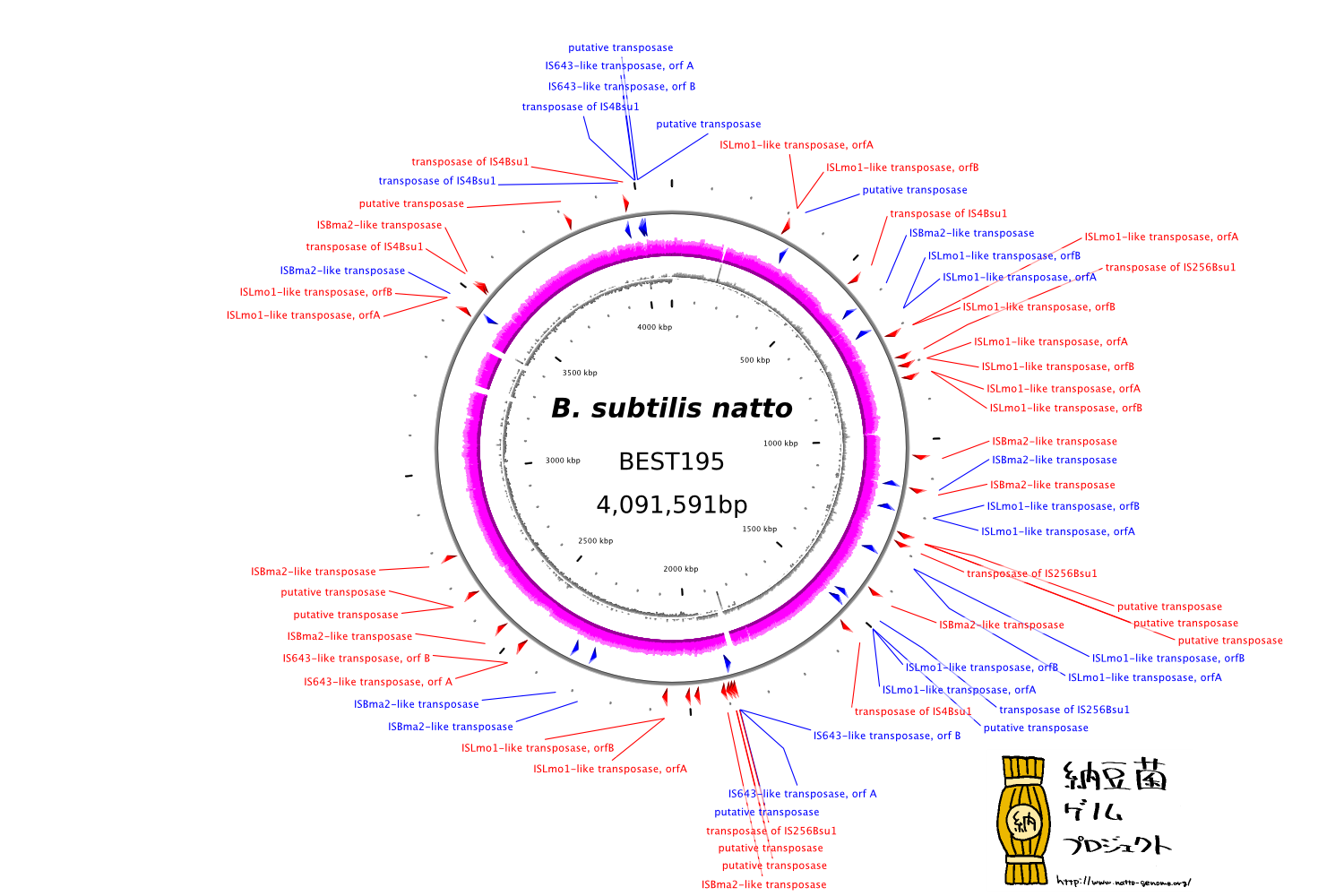
↑図は、僕らが見つけた transposon のマップ。けっこうあります。
RECONF研 (May 13, 2010)
[FPGAを用いたDC-DCコンバータ向け高速比例ディジタルPID制御方式の実装]
長崎大の浜脇さん@柴田研。
50MHz の FPGA でクロックの位相をずらして 100MHz, 200MHz での PWM.
PID の P 要素だけサンプリングレートを上げて精度をよくすることができた。
名古屋先生: DC-DC コンバータの精度が上がるのはわかった。効率にはどう貢献する?
浜脇さん: 制御回路の消費電力がそれほど大きくならないとわかった。
柴田先生: 負荷の急激な変動にうまく追従して余分な電力消費を減らしましょう、という趣旨なので、精度が上がることはちゃんと意義があります。
泉先生: 2.5ms くらい応答時間がかかるようですが、データセンターではそれで充分?
柴田先生: 負荷モデルは別に検討チームがありますが、2.5ms よりはもうすこし頑張った方がいいかもしれません。
[FPGAを用いた全探索法による可変ブロックサイズ動き予測の実現]
丸山研の学生さんの発表。
+-32pixel, 30fps で、DVDサイズの探索を実現。
+-64pixel になれば、HD対応です。その場合回路規模は16倍。
Virtex-5 で実装。BlockRAM ごりごり。スキャン方向を工夫することでメモリを旨く使っている。
オフチップのメモリもちゃんと使います。
[FPGAを用いたCLAHEの実時間処理の実現]
丸山先生が代理でご発表。
コントラスト強調で暗い部分なんかをきれいに見えるようにするが、ノイズやハイライトをうまく取り扱えるようにする (局所的コントラスト強調)。
ヒストグラム伸長よりもヒストグラム平均化に近い?
大域的コントラスト強調より、局所的にやるほうが計算量が大変。
まじめにやるとループが出てきてしまってパイプラインにならないので、違うやり方を考えた。直前の計算結果をフィードバックするところがポイント。
9bit x 256階調のヒストグラムをレジスタで並列に持っており、1clk/pixel で処理できる。
ウインドウサイズは 60×60 とか、もっと大きいのとか。あんまり小さいとノイズだらけになる。
かなり速くて 500fps くらい出るので、256 階調一気にやるのではなくて、たとえば半分の回路で128階調ずつとかにしてもいい。メモリが問題なんだけど、分割をうまくすれば意外とうまく使えそう?
[動的再構成プロセッサアレイMuCCRA-3のマルチコア化の研究]
DRPA を単に大きくするのじゃなくて、小さいアレイをたくさんならべるマルチコア化。
入出力のバッファはダブルバッファになってるんだが、入出力バッファ群とMuCCRA-Core群をクロスバを介してつないで、ぱかぱか切り替えられる。
泉先生: コアがふえたらクロスバでは大変じゃない?
さっさー: 接続は10数個くらいを考えているので、クロスバでもいいかな。
梶原さん: 各タスクに分けたときに、それぞれのタスクは同期して動くの?処理と入力データによっては処理時間に伸び縮みをしたいと思う場合もあるかも。
さっさー: 長さが変わってもそこは同期が取れます。
谷川先生: PE数を多くする場合とマルチコア化、というのを最初に出していたけど、PE数を増やすほうがハッピーな場合というのはなにか考えられますか?
さっさー: ひとつのアプリケーションで性能を出したければ普通にPE数が多い方がいいわけなので、それはそれで。
[FeRAMを用いた不揮発リコンギャラブルロジックデバイスの試作]
Vdd が下がってきたら強誘電体メモリに書き込み、Vdd 復帰時に読み出す不揮発FFを開発。
VGLC アーキテクチャをこれで作って、island style なチップを作った。
不揮発FFの面積はD-FFの9.6倍・・・FeRAM はかっこいいけど難しい。
ふんがさん: コンフィギュレーションデータを FeRAM に書いたまま使えばいいんでは?
古賀さん: 実は FeRAM は破壊読み出しなので、FF に読み出さなければいけない。
名古屋先生: LUT でもよかったのでは?
古賀さん: コンフィギュレーションメモリのビットあたり面積が大きくなることはわかっていたので、少しでも面積を減らしたくて VGLC を使うといいかな、と思った。
[高精度な科学技術計算エンジン向けディジットシリアル浮動小数点演算器]
8倍精度以上の精度がほしいとき!あります!
でも、8倍精度 (256bit) の演算器は大きくて、並列度も低くて、いまいち。
digit serial にしたら、周波数や面積はどうなる? 最適な digit 幅は?
IEEE754だいたい準拠。非正規化数はアンダーフロー扱い、丸めは切り捨てだけ。
8bit 幅の演算器で、性能面積比で 1.3倍。
小栗先生: 割り算は下位からやるわけにいかないと思うんだけど、どうしますか?
谷川先生: 除算器を作らずに加算・乗算を組み合わせてやるしかないと考えています。
市川先生: パイプラインの段数の最適なポイントはビット幅によって変わるはずですが。
谷川先生: 動作周波数が同じになるくらいのポイントでやりました。
市川先生: パラレルをパイプライン化するのとディジットシリアルは実は本質的には同じなのでは??
谷川先生: いろいろ工夫すると実は同じなのかもしれません。ただ、バス幅を小さくできるところが違うかな、と思います。
弘中先生: 本質的には同じですが、根本的に違うのは、ピン数などの自由度が上がる点が大きく違います。
市川先生: Booth 木なんかを使う場合に、途中をすっ飛ばせる可能性もありますよね。
谷川先生: 長さが変わってしまうといろいろ難しいので、検討した結果固定にしました。
あー思い切ってこういうの使ってもいいのかもなー。
[SRAM型FPGA上の実装回路におけるソフトエラー耐性評価手法の一検討]
フレーム単位で部分再構成して擬似的にエラーを注入。
TMR 化しても完全にはエラーがなくならない。
天野先生: エラーが多くないですか?
木村さん: 別々に演算器を3つ作ったはずなんだけど、同じ回路だし、ツールがくっつけちゃったかもしれません。
泉先生: コントロール系が壊れて、全然動かなくなるようなことはなかった? すごい電流が流れて熱くなっちゃうとか。
木村さん+久我先生: 組み合わせ回路で、順序回路ではないので今回は問題ない感じでした。
名古屋先生: TMR なしでも、エラー注入回数より検出回数のほうが何桁か少ないのはなぜ?
木村さん+久我先生: 回路がすかすかなので、使ってないところを壊しちゃっているだけの可能性も。本当は、ちゃんとしたアプリケーションなんかを使ってやる必要があるかもしれません。
[FPGAにおける演算パイプライン共有化のためのデータパス分類手法の提案]
小川さんデビュー戦。
名古屋先生: LUT削減率ということでしたが、もともとの数はどれくらい?
小川さん: すみませんいまちょっとわかりません。
名古屋先生: 削減率とかはあんまり変わらないような感じですが、レイテンシに着目していいものを選べばいい?
佐野先生: 32個全部くっつけたら25%くらい減るの?
小川さん+柴田先生: 25%は積分とかコミコミです。
[布線論理の性能を引き出すストリーム処理]
– pipelined FFT
– FDTD: 誘電率の違いを使って電磁波で乳がんを発見できないか? (放射線でなくて)
— Markov chain + 逐次ベイズフィルタ
— Monte Carlo 近似 (粒子フィルタ): 条件付き分布を式によってではなく、多数のサンプル値(粒子)によって近似。まさにモンテカルロ。 → これ熱いんだよね!!
– 粒子フィルタで3D認識!
– MBE: Multi-band excitation speech model
— 最近のデジタル無線で使われている。位相を考えずに、各バンドのパワーだけを使う。非常にクリアに音声が送れるらしい
– 超高速メニーコアコンピューティング研究センター
— 超並列部門: GPU
— リアルタイム計算部門
報道発表
納豆菌ゲノムの仕事ですが、ようやくプレスリリースが出ました。
明日あたり新聞とかに載るかな?
ちなみに、natto-genome.org は我らが prosou.nu のサーバでホスティングしています (笑)。
こどものひ

恵比寿にて。