[ 反転・非反転ダイナミック転光再構成アーキテクチャのエミュレーション試験 ]
静岡大の渡邊先生の学生さん。
ダイナミック光再構成アーキテクチャ: SPD で受けた信号をメモリに蓄えるのではなく、SPD の接合容量をメモリとして用いることでメモリを省略し、面積を削減する。試作に成功している。
差分光再構成アーキテクチャ: 再構成速度を向上するにはコンテキストの輝度を上げる必要がある。これにはコンテキストの明点を削減するのが効果的で、差分再構成が効果的。
反転 SPD は、複数のビットをまとめてひっくり返すのに使い、照射ビット数の削減に役立つ。メモリがある場合には簡単だが、メモリなしのダイナミック光再構成アーキテクチャに適用。
実験で使ったチップはメモリがついているが、それを無効化して使った。0.35um プロセスのチップで、波長 850nm のレーザー。再構成時間は 1.22 倍向上。
前の発表よりも再構成時間が延びている気がしますが、方式をかえたから? (名古屋先生)
→ 使っているレーザーの出力が弱いのが原因で、前の実験と同じレーザーを使えば nsec オーダーになるはず。
プロセスが縮んだら密度があがるの? SPD の間隔が重要そうですが (大阪市立大・牧野先生)。
→ まだまだいけます。いま使っている SPD は大きいですし。
[ 光再構成型ゲートアレイのホログラム部の組み立て精度について ]
ホログラムとチップがちゃんと正しい角度で入らなかったことを想定して、ホログラム側でそれを補償できるか、という実験。
ずれがわかっていればできる、ということだと思うが、どうやってそれを検出してホログラムを選択するのか? (NEC 梶原さん etc)
→ 計測手段がなくても、いくつかホログラムを作っておいて、それを取り替えて試すことで再構成できるようになる、というのがメリット。組み立て後にホログラムを差し替えられる、という前提。
再構成エラーとか (ビットが欠けてしまうとか) は考えない?
→ それはもちろんあると思うが、そのあたりまで含めて総合的に対応のしかたを提案していきたい。
一枚目のコンテキストをいろいろやってずれを検出して、二枚目以降のコンテキストを書き込むときはそれで求めた誤差を使えばいいのか。なるほどー。
[ 低エネルギーを目的とした大規模リコンフィギャラブルプロセッサアレイSMAの予備評価 ]
Silent Mega Array.
CREST のやつ。エネルギー消費を 1/100 にしたい。
細粒度 power gating を用いた CPU (Geyser) を作った。
でも、SoC で embedded CPU の消費エネルギーはわずかなので、次は SoC 中の汎用アクセラレータがターゲット?
DR の消費電力解析:
– 効率は DSP の 1/8 – 1/10 くらい
– 動的 reconfiguration は無駄が大きい
– クロック分配も
解決策:
– とにかくアレイを大きくして詰め込んで、使わないところは power gate すれば?
– 組み合わせ回路とレジスタ部を分離して、組み合わせ回路のところだけ電圧を落とす
PE array は組み合わせ回路のみでレジスタをもたない。PE array の下にレジスタファイル。PE は粗粒度で、MuCCRA から持ってきた。
16×7 PE で、65nm の 8mm 角。
PE 1段あたり 5.8nsec 、SE 1.2nsec の遅延。
2次元 DCT が 16 clk, 10MHz くらいで動きそう。
MuCCRA-1 の 4.8 倍速い。
電圧制御可能な部分の面積は 87% 。
[ マルチコンテキスト型リコンフィギャラブルプロセッサにおけるデータ並列タスクの処理法 ]
井口先生 @ JAIST のところ。
DRP-1 だ!
DR なチップを使って処理をするには SIMD が有効だが、SIMD array に充分なデータを供給するのは入出力ポートの制約があって、ちょっと大変。ストリーミングだと、入力・処理・出力・入力… となり、入出力がしんどいが、これをパイプライン的に行うことで解決。
DRP-1 のタイルを、IT: Input Tile, PT: Processing Tile, OT: Output Tile に分ける。IT は外部からの入力、OT は外部への出力を行う。それぞれのタイルは独立して動作させ、処理と入出力を常にオーバーラップして行うことで、入出力のオーバーヘッドを隠蔽。
DRP じゃなくても使えると思うんですが (NEC 梶原さん)
→ そうです。DRP の場合は部分再構成が簡単にできることと、コンテキストスイッチができることがあるので、より有効です。
IT とか OT とか PT は、これ以上分割してパイプラインにはできない? (名古屋先生)
→ 難しそうです。
[ 粒度可変論理セル向けローカルインタコネクト構造の提案と評価 ]
VGLC は 21 本も入出力ピンがあり、接続が大変そう。
セルのアーキテクチャ自体をいじるのは大変なので、VGLC と connection block の間に LCB というのを入れて、信号数を削減することにする。
素直に作ったら、VGLC が 682Tr に対して LCB が 3484Tr と、大きくなりすぎてしまった!
削減する方法を検討して、4種類を実装。
LCB を入れることでどれくらいハッピーになれるのでしょうか (名古屋先生)
→ まだ外部配線などの評価ができていないので、どうなるかはわかりません。
入れないほうがいい、ということもありうる?
→ 条件によってはそうなります。外部配線をどれくらい入れるか、とかがまだ決まっていないので一概には言えないが、外部配線をたくさん用意した場合には LCB が必要なのではないかと思う。
[ Turnモデルに基づく二次元トーラス網の適応ルーティング ]
2D mesh 向けの、North First ルーティングを 2D torus に適用するためのNF+1 というルーティング手法の提案。
むむー、わしゃこういうのは苦手じゃけー、みんなかっこよく見える。
[ 階層型相互結合網における適応型ルーティングのハードウェア実装コストの検討 ]
オンチップマルチプロセッサ向けの階層型相互結合網 TESH に適応型ルーティングを適用する、というお話。
TESH の一番下は mesh. それをいくつか torus でつなぎあわせた形。
制御回路を VHDL で実装し、FPGA をターゲットとして評価。ルーティングアルゴリズムの実装を追加したことによる HW 量の増加は少ない。
ターゲットデバイスは何? (ふんがさん)
→ わかりません (なんだってー!!)
ISE Webpack だから SPARTAN かなぁ。でも初代かなあ。
シミュレータでの性能評価と実装での性能評価に差があったりする? (宇都宮大 森さん)
→ 今回はルータに入ってから出るまでの時間の評価なので、いままでやっていたものとは違う (という趣旨であってるかな)
[ FPGAのスイッチマトリクスを対象とするソフトエラー対策 ]
配線要素のエラーを検出する必要もあるよね。
– 3重化多数決論理パストランジスタ (MAJ: 既存手法)
– ASRAM (asymmetric SRAM) を使う (提案手法)
など。
パストランジスタを二重化したりしても、MAJ は自乗のオーダーなので非常に強くて、なかなか勝てない。しかし、メモリを二重化することで間違って on になる確率、off になる確率ともに改善。実際の configuration bit の 0/1 の偏りを考えると、ASRAM でも充分いける。2重化だと、トランジスタ数でもMAJに勝てる。3重化はさすがにダメ。
宇宙とか地上とかは想定されていますか? (尼崎先制)
マルチビットSEU を想定されている?
→ はい
FPGA では配線部がほとんどになっているわけだが、それを多重化するということは現実的なのでしょうか?
→ 難しいのではないか、と思うのでこれから評価をしていきたい。
[ 高性能差分法計算のためのFPGAアレイにおけるFPGA間通信機構の検討 ]
差分法を解くためのアレイ型計算機を FPGA で作る。
パイプラインが複数の FPGA にまたがるのと違って、PE がいくつか FPGA に入っていて、隣接 PE / FPGA 間では差分をとるための通信だけをすればいい、というのだとバンド幅が少なくてもすむのかな…
PE の中身は積和演算。
パイプラインが FPGA 間にまたがる場合と、PE がうまく FPGA に収まる場合は全然違う? (おさな)
→ そりゃそうです。PE のなかのパイプラインはぎっしり詰まってるし、制御信号もあるし… 今回の実装は、PE の中身が積和演算なので、わりとうまくいっているけれど。
あーあーあーあーあー、そうだよなー。
そううまくはいかないよなー。むー。
しかし、粗粒度デバイスみたいな感じだが、そういう単位で PE を作って何とかする、というのはヒントになったような、ならなかったような。
カテゴリー: Conference Logs
RECONF / Sep. 26, 2008
[ 科学技術計算エンジンに使用するディジットシリアル浮動小数点演算器の開発 ]
多倍長演算器を構成するために word parallel ではなく、digit serial の演算器を作った。面積では圧倒的に小さくなるはずで、面積あたりの性能では、高精度の場合に DS な FP ALU のほうが有利になると考えられる。
作ったのはまず、 DS な integer multiplier と divider (これが一番大きな面積を占めるので)。 それを使って FP ALU を作った。デバイスは Rohm 0.18um.
面積あたりの FLOP 数は word parallel に比べてちょっと下がっちゃったが、まだ合成だけでレイアウトをしていないし、レイアウトをすれば word parallel が悪くなるかも。
10進演算器にも応用できる? (井口先生) → できると思うがまだ考えてません。
入力がすべてくるまで中の処理ははじまらない? (天野先生) → 指数部、仮数部、符号の LSB から入れるようにして、最初のデータがきたらすぐスタートするのだが、入出力に数サイクル掛かるのは仕方ない。
バレルシフタは所要サイクル数がデータに依存すると思うが、それによって性能が変わったりはしないの? → worst case に合わせて設計してあります。
乗算器は 1 クロックでやってるの? (泉先生) → DS でも word parallel でも、パイプラインにはしていません。
パイプライン化したらどうなる? → word parallel のほうは性能があがると思うが、入出力のポート数が少ないアドバンテージはかわらないので、そこはいいかなと。
消費電力が下がったりはしませんか? (梶原さん) → 検討させていただきます。
[ 粒度可変論理セルにおける入力粒度最適化の一検討 ]
熊大の学生さん。
VGLC (Variable Grain Logic Cell): ALU と LUT の hybrid cell.
VGLC は複数の BLE (Basic Logic Element) から成る。BLE は LUT と同等のランダムロジック表現と、misc logic という、より入力ビット数の多い (ただし論理関数空間のカバレッジが 100% ではない) 論理関数表現モードを持つ。
BLE の入力数 (入力粒度): ひとつの BLE に実装できる canonical form の入力数を変化させる。
たとえば、
入力数2: 2-LUT と同等の機能、4-misc logic まで実装可能
入力数3: 3-LUT と同等の機能、5-misc logic まで実装可能
のような感じ。
MCNC benchmark で評価。粒度を大きくすると当然使用論理セル数は減少するが、それ以上にセルの面積増加が深刻になる。また、あまり粒度を大きくしても論理セル数の減少は緩やかになって、悲しい。これは、入力ビット数が増えると misc logic で表現できる論理関数のカバレッジが急激に下がってしまうので使用される機会が減ることに一因がある模様。
でも、入力数の多い CF はメモリ使用率の向上に効く。
Elias Ahmed and Jonathan Rose: “The effect of LUT and cluster size on deep-submicron FPGA performance and density” (IEEE Trans. VLSI)という論文が要チェック。
BLE の粒度がかわると BLE の遅延が変わったりはしないの? (谷川先生) → すこしかわるけど、それほど大きく変化しないはず。
Misc と CF とどっちを優先して technology mapping する? (泉先生) → HeteroMap をもとに作っている。基本的に段数最適化。
[ 動的リコンフィギャラブルプロセッサ MuCCRA-2b の実機評価 ]
動作中の LSI は AC 成分がいろいろあるわけだが、テスタで測った電力はどれくらい正確だと思っている? (泉先生) → まあ、桁がわかっている程度かと
画像が乱れた、というのは目で確認している? → はい。いちおうロジアナでも見てますが。
複数PE分を時分割で emulation していて、配線相当分が入っていないと考えていいですか (梶原さん) → はい。でも、PE 内のは入ってます。
最高動作周波数は I/O が絡む形でやっている? (渡辺先生) → 実機評価ではメモリが外にあるので、I/Oも入ってます。FPGA の I/O 遅延も入ってしまうけど…
開発環境は -2 と -2b で同じ? (谷川先生) → 同じコンパイラで作って、(コンテキスト配送がいらないのでそこのところを) ちょっといじってる。
[ ソフトコアプロセッサの高信頼化に向けた三重冗長実装の一検討 ]
一宮さん@末吉研。
Permanent error: LUT, interconnection, RAM などで起きる SEU
Transient error: FF で起きる SEU
MicroBlaze を3つ並べて voter をつける。でも、voter をつけると CP が長くなるらしくて、2割くらい動作周波数が落ちるのと、メモリを3倍食う。
メモリは 3 つの MicroBlaze で共有することで解決するが、さらに 25% 周波数が下がり、オリジナルと比べると 41.5%…
性能を稼ぐためにキャッシュを使うアプローチも。BRAM をキャッシュとして使い、メモリは外部の DDR SDRAM. この場合は voter が DDR SDRAM コントローラの手前に入る。動作周波数はかなりいいが、SDRAM コントローラが大きいのが問題。
メモリは TMR で一番重要だと思うんだけど共有しちゃっていいの? (渡辺先生) → ECC とかあるので、いいかなーと。
SEU の試験方法に何かいいのはある? → bit file を壊してみるとか。
キャッシュを共有してvoter を入れる、というのはどうでしょう? (谷川先生) → MicroBlaze からキャッシュを切り離さないといけないので、ちょっと難しいかもしれません。
[ 書き換え可能ハードウェアを用いた体故障性能向上手法の研究 ]
山口さん。
(面白いネタをたくさん仕込むぜ!と意気込んでおられたのでばっちり録画しました。うひひ)
[ 再構成デバイス MPLD への組み合わせ回路マッピング手法の検討 ]
小田さん@広島市立大。
MPLD は他の PLD と基本構成が全然違うので、マッピングツールが必要。
コンフィギュレーションはメモリへの書き込み動作と同じなので、高速。
メモリとしても PLD としても使える。
基本要素は MLUT で、基本的には LUT と同じ機能で、DP-RAM の片方のポートをメモリ動作用、もう片方を LUT 動作用にしている。配線は固定されており、MLUT がスイッチにもなるようだ。
テクノロジ非依存最適化のところは design compiler で、2入力以下の素子しか使わないようにやる。テクノロジ依存のところ+配置配線は自前。
配線4のときは PCA の Plastic part だ! 1 bit adder とかシフトレジスタみたいに並べられるものはいいけど、配線のほうが大変じゃないかしら。論理を削減しようとして頑張っても、配置配線のほうがずっと重要になる可能性が高いと思います (泉先生) → 今回はそれほど詳しく説明してませんが、次回お楽しみに。
ひとつの MLUT のサイズは? メモリとして作ると、ある程度大きい方が効率がいい (井口先生) → 6 入出力対なので、2^6 x 6
実装例が adder とかなので、算術演算以外の (きれいじゃない) ものもやってほしい
かっこいいんだけど、配線が全部メモリを通るのはちょっと実用的にしんどいかもしれない (ふんがさん) → 実は検討してます。
あと、入出力の数が同じ、というより、入力のほうが多いのが自然かも。
RECONF / Sep.25, 2008
[ FPGA を用いた2次元液体運動シミュレーションの高速化 ]
会津大の佐藤さん (チームオクヤマ)。
無衝突系重力多体問題のベンチマーク
– Cell 125GFLOPS
– GeForce8800 653GFLOPS
– GRAPE-7 728GFLOPS (Altera Cyclone)
PROGRAPE-4 を使った。
必要最低限の演算精度の見極め。
格子を使う差分法やFEM と、ラグランジュ的に必要に応じて粒子を発生させる Smoothed Particle Hydrodynamics (SPH) 法などがある。災害シミュレーションのような、大きな形状の変化を伴うものを想定して後者を使った。粒子間の相互作用として水の動きを計算することができるが、精度を高くするためには粒子の数を増やす必要があり、計算量がしんどくなる。
2次元ダム崩壊問題を、double と 仮数部 12, 14, 16, 18 bit with 8bit exp の5つの演算精度で解き、平均自乗誤差 (MSE) で評価。仮数部 16bit で充分な精度が得られた。
(質疑)
転送はどれくらい?→ 転送オーバーヘッドを隠蔽するために粒子を使い回すようにする。一度 broadcast memory に入れたものを particle register に入れたり。水の場合は重力多体問題より狭い範囲で相互作用するので、3割くらい。
精度検証はどうやってやった? → 仮数部を AND でマスクします (うお、そうか! それなら僕らにもできそうだ・・・)。
粒子が増えたりすると必要な演算精度はかわる?→ 単純に粒子数を増やしても必要な演算精度はかわらない (指数部は必要になるかも?) が、粒子がどこまで近づくように定義するかで仮数部の必要ビット数が変わる。
ひとつの FPGA にふたつのパイプラインが載っているということだが、どれくらい演算器がのっていて、どれくらいほしいと思っている? → 理想は4パイプライン。
[ 動的再構成可能プロセッサへの JPEG エンコーダの実装と評価 ]
岡山大の古島さん (名古屋先生の学生さん)。DAP/DNA-2 に実装。DNA (reconfigurable array) に実装したのは次のふたつ:
– RGB → YCbCr 変換。Cb と Cr は情報量を落とす : 1面に4並列
– 2次元 DCT (2回の 1次元 DCT で実装。バタフライ演算) : 3面に2並列
再構成とかの制御オーバーヘッドがあるので、ふつうの CPU と比べた場合には、画像が大きい方が有利になる。でも、色変換と DCT 以外のところをやる DAP がボトルネックっぽい。エネルギー効率は x25〜52 (compared to Pentium4)。
(質疑)
どうして表色系の変換と DCT を選んだ? → ハフマン符号化とか量子化のところはメモリアクセスが複雑で、そこが DNA に向かない気がしたので。
DCT の実装が 3 つの構成情報にわかれているが、どうやって分割しているか? → バタフライ演算の4ステージが2面に分かれている。それをそれぞれ2回使って縦横でやる。
[ FPGA を用いた生化学シミュレータにおける… (以下略) ]
[ 分散共有メモリの接続を変更可能な PC クラスタ用 SW の提案 ]
必要な資源のみを結合する疎結合型の PC クラスタ。
問題の性質によって結合を変えることができれば、資源効率のよいクラスタ構成を実現できそう → 可変構造型ネットワーク。
まずは DSM をターゲットにしてみることにした。アドレス変換による仮想共有メモリ。
基本的に固定経路で、疎行列計算とかに向く (はず)。
Switching fabric を小さくしつつポート数を稼ぎたいのか? でも実際のところ、最近の問題はもはや、充分なサイズのクロスバがチップに載らないということではなくて、ピン数なんじゃないのか? とか思ったので、一応突っ込んでみた。
でも、データの使用頻度を考慮したインタコネクションというのは面白そう。
[ レーベンシュタイン距離を用いた道路標識認識アルゴリズムの FPGA 実装 ]
ITS: automatic cruise control とか lane keep system が実用化されている。
より高度な動画像認識として道路標識認識システムとか。
標識の切り出しがずれても認識は大丈夫! という仕掛けにしたいぜ。そこでレーベンシュタイン距離 (いわゆる edit distance みたいなやつ) を導入。
赤色・青色分解をしたあとに文字列変換して、テンプレートマッチング。
テンプレートマッチングは2段階。大分類 (丸とか四角とか三角とか) でまず分けて、そのあとに細かいテンプレートにあてる。
標識の数は同時にどれくらい? → いまのところひとつでやっているが、現実には複数の標識が一枚のフレームにでてくることはありうる。現在の処理時間は標識ひとつだけの場合。
車載カメラで撮ると歪まない? → わりと tolerant ではあると思うんだけど、前処理でなんとかしなければならないかも。(わし思うに、歪むのは広角のレンズで近くの標識を撮るような場合で、しかしそんな近くの標識を認識してなんかいわれても運転者は困るわけで、認識の対象はある程度遠くの標識でなければならないのではないだろうか。そういう場合にはゆがみの影響はないよね)
[ FPGA による並列計算機用2次元ネットワークの実機評価システム ]
岡山大の小畑先生チーム。
ネットワークの動きは、シミュレーションではわからないこともある (と、RHiNET-2 の論文に書いてあるらしい :p )。そこで、torus だの mesh だのをいろいろ試すためのシステム。
FPD (DVI じゃない、ちょっと昔に見かけた液晶用のコネクタ。組み込みではいまでもつかってるのかな?) のケーブルを 4 リンク使える NIC. データを記録するための global clock / reset も備える (これは通信には使わない)。
API としては、MPI のサブセットを実装。
ちゃんと並列プログラミングしたりして評価もとっており、手堅い仕事だと思う。楽しそう。
[ FPGA クラスタのためのオペレーティングシステム機能の試作 ]
広島市立大。
従来はバスによる密結合型 FPGA クラスタを扱っていた。今度は Ethernet (通信) と USB (configuration) を使った疎結合型 FPGA クラスタを構築。誰でも簡単に構築できるシステム。性能よりプログラム資産の構築を追及。
制御用独自プロセッサは 16bit で、Picoblaze より強力かつ Microblaze よりは小さい。
[ 招待講演: オペレーティングシステムとリコンフィギャラブルハードウェア ]
谷口先生。
OS には常に性能が求められているので、ハードウェア処理による性能向上を考えたい。
OS の性能低下要因: ディスク I/O とメモリ間データ転送 = 何かを作るわけではない操作なので、どちらも本質的には必要ないはず…
他にもいろいろあるのだが、なんかすごかった。
FPL ’08: Day 3
[ Synthesis ]
#1: Floating Point Datapath Synthesis for FPGAs
Altera の人のプレゼンテーション。
Floating Point Compiler
データパス上で必要な値域や例外は予測することができるので、すべてのノードを IEEE754 に従わせる必要はない。新しい浮動小数点型を定義して、それを使う。正規化と例外処理はしない (例外検出は行い、それは次のノードに送る)。正規化とかしないのは、バレルシフタがやばいから。
– 200+ MHz double precision: 50GFLOPS – 3SE260
– 250+ MHz single precision: 100GFLOPS – 3SE260
やっぱ演算器は作らなきゃいけない、ということだね。ちょっと参考になりそうだ。
#2: Automatic Generation of Run-time Parameterizable Configurations
TMAP: Tunable LUT mapping
FIR フィルタとかの係数をレジスタに書いて演算器で処理する形式から、決めうちにした回路に reconfiguration して使う方法。
– 1999LUTs → 1008LUTs
– 8.4MHz → 11.9MHz
いいんだけど、configuration に時間が掛かる上に、構成情報のデータベースが大きくなるのが問題。これを、うまく coefficient に関係するところだけランタイムで作ってなんとかする話。
– 1301LUTs, 11.5MHz
VHDL に annotation を入れて、それを合成するようなツールを開発。
#3: Generation of partial FPGA configurations at run-time
動的再構成するモジュール間を Bus macro みたいなので、つなぎかたをきめてしまうのではなくて、route table をもつ共通のインタフェイスで接続することで簡単にする。
Route table がもつのは、
– connection ID: relative coordinates of the endpoints
– route specification: list of frame and bit indices of all sw points in the route
– incompatibility information
そんな感じ。
[ Optimization ]
#3: Memory access parallelization in high-level compilation for reconfigurable adaptive computers
Adaptive computing system: CPU + reconfigurable hardware
高位言語からの合成に関する研究の多くは科学技術計算 = regular memory access, loops with constant bounds, perfectly nested loops がターゲット。そうじゃないものを扱うのに問題になるのは、ポインタ。
control flow graph を作って、activate token と cancel token を使う。Token を使うことで依存関係を壊さずにメモリアクセスを並列に行ったり、serialize したり、speculation したりする。
FPL ’08: Day 2
Keynote 3 は 8:30 から… 無理です。
[ Compilers for Reconfigurable Architectures ]
#2: CHiMPS: A C-Level Compilation Flow for Hybrid CPU/FPGA Architectures
Xeon のソケットに挿す FPGA をターゲットに考えている。
Spatial DFG にして並列性を抽出してハードウェア化。
どこを HW に落とすかは pragma を使って指定する。あと、ポインタをほげほげする restrict というキーワードがある以外は、ふつうの C 言語。
メモリからとってくるデータをキャッシュするためのメモリをたくさん用意する。これでレイテンシを下げたり、競合を減らしたりする。キャッシュの一貫性を維持するプロトコルはちゃんとやるとコストが大きいので、書き込みができるのは一度にひとつだけ。Direct mapped cache.
うーん。C から design entry する限りは結局、キャッシュとかそういう Von Neumann の呪縛からは逃げられないのかなー。
小さいキャッシュがたくさんあると、それをメモリコントローラにつなぐところが大変じゃない? →そうでもないぜー
マルチコアとの関係は?→ それもやりたいね。あと、浮動小数点関係とかね。
#3: Combining Data Reuse Exploitation with Data-Level Parallelization for FPGA Targeted Hardware Compilation: A Geometric Programming
Memory subsystem と loop level parallelism の co design.
どの loop nest level で使われるデータ化で、off-chip にするか on-chip にするかをきめる?
むー。こういうことは考えているのだが、この研究のように定式化するところが難しそう…
メモリの使い方でクロック周波数はかわる? → 変わるけど、サイクル数のほうが実行時間に対して支配的。
[ Random # Generation & PLL ]
#1: Sampling from the Exponential Distribution using Independent Bernoulli Variates
固定小数点の、指数分布の乱数を作る方法。exp() を使わないで高速にやる。
よしみさんが cite されてた。
将来的には fixed-floating conversion を使わずに、直接に浮動小数点の値を出せるようにしたい。
#2: Enhancing security of ring oscillator-based TRNG implemented in FPGA
ring osc を乱数生成に使う場合、電源からのノイズとかがけっこう問題。気をつけましょう。気をつけて実装すれば deterministic jitter はけっこう減らせる。
[ Tutorial: Virtex-5 FXT: A new FPGA platform ]
Virte-5 FXT: has PPC440 instead of PPC405. Super-scaler, larger caches, deeper pipeline.
Not just a PPC440, but with: 5×2 crossbar connection, memory interface, 32bit DMA, user defined instruction (by APU), single/double IEEE-754 compliant 128-bit FPU (soft core) …
GTX high-performance transceivers: 150Mbps to 6.5Gbps
Power dissipation = 250mW / channel or less
TXT Family: FX without PPC, but twice # of GTX transceivers. ES 4Q08, MP 1Q09.
8 to 24 transceivers for FXT family, 40 to 48 in TXT family.
Device availability の保守についてはどう考えている?
XC3000 は 15 年前の製品で、まだ売ってるけど、いまからデザインするならば新しいのを使いましょう。1年の FPGA の進歩は人間の15歳分だよ!
でも、binary compatible にすることは考えていません。
[ High performance Computing for Financial and Biological Modeling ]
#1: FPGA Acceleration of Monte-Carlo Based Credit Derivative Pricing
single/double precision floating point の hybrid design とかをしているところが面白そう。構成のおもしろさでは 443 さんの仕事のほうがずっと上だな。
#3: Acceleration of a Production Rigid Molecure Docking Code
FPL ’08: Day 1
[ Opening Keynote ]
FPGA is the programmable platform for Transforming, transporting and computing digital data.
Triple play opportunity:
– DSP
– Packet processing
– Tera computing
Network Trends:
– Global IP traffic will reach 44bn gigabytes / month in 2012, while less than 7bn in 2007.
– Video goes 22% of consumer traffic in 2007, will be 90% in 2012.
– Mobile data traffic will roughly double each year from 2008-2012.
→ focus on reducing power consumption to reduce operating expense.
Stanford Open Slate Program
– Programmable Open Mobile Internet
– 25 Stanford inter-disciplinay faculty + Cisco, Deutsche Telekom, DoCoMo, NEC, Xilinx
Virtual operating system is available: next step is virtual network!
– High speed / reliability / security : various demands
– packet level reconfiguration !?
そのほかいろいろ
– Packet based on-board interconnection
– MIMO, Multi mode radio とかは信号処理の量がヤバい
– Heterogeneous multiprocessing: Intel + FPGA (on FSB)
University Program:
– XUPV5-LX110T
– 周辺回路もりだくさん。PCIe もついてる。やべえ、楽しそう
– OpenSPARC evaluation kit も…
[ NoC session ]
#2
Coarse grain reconfigurable architecture + multistage interconnection
Good old MIN!
2-input 2-output だけど、大きいのは考えなかった? → そのうちねー
#3
many core なシステムへ向けたお話。
programmable router より NoC のほうがいいよ、みたいな。
なんか、両方ともわりと普通の話だったので、ちょっと残念。
[ Keynote #2, FPGAs at CERN ]
CERN では加速器のまわりの、大量の検出器からの信号を処理するのに FPGA を使っている。加速器なので、当然ヤバい粒子がいっぱい飛び出すわけで、radiation がすごいところは古いチップ (Virtex-II Pro とか) を使ってエラー率を下げるみたいな話しも。
[ Image & Video ]
How fast is an FPGA in image processing?
この間の RECONF で聴いたお話とだいたい同じ。ソフトウェアは Intel C++ 使って評価してるのかー。いいかも。
SIMD はプログラミングが大変だといっていたが、使わなかったら speedup はどうなるか? → 測定してない。プログラミングの得意な学生が実装しました。
DSP とか GPU を使わないのはなぜ? → intel のプロセッサはみんなが持っているから。
FPGA Hardware Acceleration for H.264 Motion Estimation
フレームを16×16 のブロックに区切って、SAD が最小になるところを見つけ、motion vector を求める。
256 subtraction+accumulation / SAD → 96giga / sec.
H.264 ではブロックのサイズをフレーム内の場所ごとに選べることと、複数のフレームを reference として選べる (鳥が羽ばたいたりとか、そういう periodic motion をうまく扱えるようになる。たいていの実装では 4 つの reference frame を使う) ことが違う。計算量は 4 倍ちょっと。
1.5 giga macro-reference block access / sec。メモリアクセスも最適化しないとやばい。
Real Time Image Super Resolution on an FPGA
Imperial College のひと。うおー超解像だ!
複数の低解像度のフレームから高解像度のフレームを合成する。
Frequency domain approach と spacial domain approach がある。やったのは後者 (だと思う)。
1. Motion Estimation
2. Image Reconstruction
3. Image Quality: Deblurring, Denoising
ハードウェア処理に適した SR アルゴリズムを開発した。2, 3 を実装している。
XC2V6000 で 1280×720, 61fps 出る。いまのところ、ふつうの HDTV にはこれで充分だし、FPGA のリソースを全部使い切っているわけでは全然ないので、もっと小さいのでも載りそう。一番必要な資源は multiplier. 固定小数点だが、浮動小数点による実装と比べて目に見える違いはない。
RECONF2008: 1-xx @ 会津大
[ 部分回路再構成を利用した耐故障性向上アーキテクチャの提案とその実装 ]
壊れたブロックを置き換えたときに、壊れてるところから配線に信号が行っちゃわない?
大丈夫だそうです。
[ 高精度浮動小数点演算器のFPGAでの実装 ]
倍精度だと CPU と勝負するのは厳しいが、四倍精度だと CPU でも emulation になるので、四倍精度の演算器が FPGA にいくつか載れば、CPU に勝てる可能性がある!
乗算は仮数部の下の方とか捨てちゃってもいいよね。
加減算はシフタが巨大になる… 絶対値の比がものすごく大きくて情報落ちが発生するような状況でなければ、多少サボれる。
[ 部分再構成システムにおけるAES-GCMを用いたビットストリームの秘匿と認証 ]
認証暗号 (AES-GCM) を使って、秘匿と認証を同時に行う (2000年くらいから出てきた概念)
Altera は Stratix IV GX で部分再構成に対応らしいぞ!
AES+SHA より小さくて速くなった。
[ FPGAにおける標数5の楕円曲線演算の高位合成を用いた実装 ]
楕円曲線ってソフトウェアでもRSAなんかと比べて遅いの? はい、とても。まだ実用化されてない。
[ ディジットシリアル演算を導入した ]
[ MXコアのMIMD型PE間データ通信における経路決定手法の提案 ]
SIMD から MIMD にして、逐次処理でも性能が出るようになったが、制御が大変。
PE 間のデータ通信も SIMD 的に、全部の PE が同じことを同時にやるのではなく、個別に指定できるようにしたい。
[ A Link Removal Methodology for Application-Specific Networks-on-chip on FPGAs ]
X-Y routing より難しいルーティングを提案してるけ、もう少し賢い、大きな (面積を食う) ルータが必要?
source routing なので、そんなことはない。
[ 粒度可変論理セル向けクラスタ構造の一検討 ]
ALU: 算術演算に向く
LUT: 論理演算に向く
これがデバイスによって規定されてしまうのは都合悪い。2入力標準型とFAをくっつけたロジックセル。
いままではセルをそのまま並べていたのをクラスタ化する検討。
クラスタ化自体の効果は? ローカル配線による性能向上がでてるだんだけど、スライドはありません。。。
[ RapidMatriX: Algebraic Path Problemのための 2D array processor ]
Algebraic Path Problem: グラフ理論みたいなやつ。
2D SIMD array
3入力1出力の複合演算器。FMA のほかに大小比較やブール演算を含む複合演算を実行。
[ パワーゲーティングを適用した動的リコンフィギャラブルプロセッサの設計と評価 ]
斉藤くん。
電源の GND に高閾値電圧のスリープトランジスタを入れて、ブロックまるごとを殺すのが従来のやりかた。粒度も大きいし、wake-up にも時間がかる。
宇佐美研ライブラリはローカルな GND を作って、そこにスリープトランジスタを入れる。細粒度で制御することができて、 wake up < 5ns。損益分岐点をちゃんと計算していれてやらないといけないのと、ネットリストを加工して挿入しなければならないのがちょっと問題。
全体でリークが多いのは ALU と SMU. Pickout は小さなモジュールで、あまりリークしないので、削減効果は少ない。
ALU + SMU を同時に sleep/wakeup するのと、別々に制御するのと検討した。同じくらいの利き方のときもあるが、後者の方がズバッと効くこともある。面積オーバーヘッドは 7-14%.
レジスタファイルってけっこう大きいから、レジスタファイルを残してほかのところを削ってもだめなんじゃない?
それは心配したんだけど、実は ALU のほとんどは乗算で、それが結構大きいので、意外と大丈夫です。
[ 銀塩ホログラムメモリを用いたマルチコンテキスト・ダイナミック光再構成型ゲートアレイ ]
いままでの光再構成型ゲートアレイは、SPD に FF がついていた。新しいのは、SPD の接合容量を使って SPD 自体をメモリとして使うことで、FF を排除する。面積は減るんだけど、バックグラウンド光が入ったりすることで回路の保持時間が短くなったりするのが心配。
いままでは液晶をホログラムの代わりにしていた(簡単だし)。こんどは銀塩を使います。銀塩だと、ホログラム作成装置が必要。He-Ne レーザ (633nm) で書き込み。コンテキストあたりの面積は液晶の 1/4 以下。
AND 回路を作ってみた。configuration に 69ms で、回路を維持できる時間は 189ms.
ただし、いまは He-Ne レーザーがつきっぱなしで、それがバックグラウンド光の原因にもなっているのを、半導体レーザーとかにすればもっと回路を維持できる時間を延ばせると思う、とのこと。
SPD の面積は LUT とかに比べるとどれくらい? (ふんがさん)
ひとつ 25.5um 角のを使ってるので、すごく大きい。でも、最近の SPD は 1um 角くらいにはなる。
銀塩ホログラムって一枚いくらくらい? (尼崎先生)
数千円くらい。最終的には銀塩じゃなくて、 3D なホログラムを使いたい。
光学系が大掛かりで製品化は難しそうだけど? (NEC 梶原さん)
パッケージに入れるような場合には、チップ自体からレーザーを出して反射させるようなやり方もありで、将来的にはもっとコンパクトに作れると思う。
[ 4コンテキスト光再構成型ゲートアレイによる高速再構成 ]
いままでに出せた最短の再構成時間は 41.7ns.
構成を高速化するにはコンテキストの輝度を高くするのが簡単。単純にこれをやるのは高出力レーザーだが、かわりにコンテキストの明点のビット数を減らすことにした。電力と過熱の問題を回避できる。
反転フォトダイオードを用意して、コンテキストのビットをぽちぽち書き換える方式。
He-Ne で全体を構成し、半導体レーザーで部分再構成。
10コンテキストあったらすべてのコンテキスト間での遷移の差分 (90パターン) を用意するのは大変じゃない?
実用的には LUT のパターンを書き換えることが多いだろう、ということでこうしている。
全体を書き換える方法ももちろん考えています。
[ FPGAを用いたストリーム処理に基づくステレオ画像の特徴点抽出法の検討 ]
小栗先生。
ストリームによるリアルタイム処理で観測・認識・動作を一体化する。
ロボットビジョンでは「とりあえず」メモリに全部データをおく、というのが前提になっちゃっているんだけど、これをやめましょう。カメラからの映像をそのままストリーム処理で分析して、カメラの位置を変えたりする。
メモリのバンド幅の問題とかがないのでいい感じの実装ができた。
記憶がない、というのは無理なんだけど、ランダムアクセスなメモリ (画像とか) には貯めない。シフトレジスタとか FIFO が基本。
こうするとすごく電力が減ると思うんですが、どれくらい効くかわかってますか? (奥山先生)
まだいろいろなものが一桁くらいいけると思うので、これからやろうと思います。
[ An Approach for Downscaling Images for Real-time Pattern Detection ]
VGA 以上で実時間処理。100MHz で 10 clk / pixel くらいが目標。
さまざまなサイズのパターンを検出しなければならない。
テンプレートをサイズをかえて用意する? 拡大縮小する? 後者にしました。
テンプレートの縮小は平均画素法。n/m 倍に縮小する時に、n 倍に拡大してから各画素の平均をとりながら 1/m する。計算量は大きいが劣化は少なくて済む。
外部メモリをひとつ使用。
XY 別々に拡大縮小できるので、ななめに撮影されたものにも (ある程度) 対応できる。
縮小回路は 2084 slices! (パターン検出回路はまだない)
いいね。
毎回テンプレートを大きくしたり小さくするのはなんで? (柴田先生)
システム全体を小さくしたいので。
回転は? (柴田先生)
パターンを回転させると、w x w のパターンについて w^3 あるので、ちょっと大変だなー、と思っている。なんとかしたい。
[ How fast is an FPGA in image processing ? ]
FPGA と最新のマイクロプロセッサの性能比較。
フィルタ・ステレオビジョン・K-means clustering. どれも演算量は多いがわりと簡単で HW 化が有効。でも、SSE3 で
128bit に対する SIMD も毎クロックできるようになった。
FPGA による速度向上率は残念ながら 5-15 倍程度で、マイクロプロセッサでも 30fps の処理ができるようになっている。
電力とかの評価は今後。
ただしFPGA 側はボードが古くて、メモリとかがあれなので、もうちょっとなんとかなるかも。メモリの性能は重要。
プロセッサと FPGA のプロセス・チップサイズを揃えたりして評価するのが重要かも (渡辺先生)
でもそういうデータは手に入らないので、気軽に買える程度、というところで揃えている。
Core2 じゃなくてグラフィックプロセッサを使ったりすると厳しいですか。DSP とか (安永先生)
GPU はクセがあるのでどうだか (乗るか乗らないかもあるし) わからないが、負ける問題は負けるかもしれない。
DSP も... Core2 がこんなに速いとは思いませんでした。
CPU のほうの開発も SSE なんかが入って大変だと思いますが、開発時間はどうですか
両方ともけっこう大変。個人差もあると思うが。
[ An implementation of a watershed algorithm based on connected components on FPGA ]
丸山先生連続でご登壇。
もともと降水の様子をシミュレーションするアルゴリズム。画像処理にも使える (というか画像処理に使う)。
外部メモリの使い方が肝。
ソフトに比べるとどうなんすか? (ふんがさん)
まったく SIMD とか使わないのに比べると x50 とか。SSE とか使われると怖いなー。
[ 複数FPGAを有するシステムでのOS機能の試作と評価 ]
SW/HW 協調処理システムで、マルチユーザで FPGA を使うようなシステム。
HW task 間での通信をサポートするような機能はある?
ありません。
いっぱいタスクがある時の context switching は?
ないので、使っている SW task が終わるまで待つしかないです。
[ 動的再構成可能ハードウェアのコンテキスト仮想化手法 ]
DRP なんかでも、コンテキストの数には限りがある。
コンテキストの遷移シーケンスをプロファイルして、統計情報をコンテキストグループの生成に使用する。分岐予測みたいな感じ。同時に入れるコンテキストをどうセットにするかで、コンテキストを外部メモリとの間で詰め替え直す回数が変わる。
遷移プロファイルがデータに依存しないようなアプリケーションでは静的にやれる。大きく変わるような場合は動的な判断が必要なので、ちょっと考えないといけない(=次の発表)。
prefetch はしていないの? 評価は LRU と比べているが、理想はどんなものかしら (佐藤さん@日立)
prefetch は、まだしてません。LRU とプロファイルを組み合わせるような方法を考えたい。
制約コンテキスト数、というのはグループの大きさ? 大きいほうがいいの? (ふんがさん)
やたら大きくすると余計なものがグループに入ってしまうので、必ずしもそうとは限らなくて、大きくすると逆に遅くなることがある。LRU だとそういうことはないけれど。
[ 動的再構成可能ハードウェアのコンテキスト仮想実行支援機構 ]
コンテキスト番号の論理物理変換を導入。全体のクリティカルパスがながくなってクロックが遅くなる (変換のところをパイプラインにすると、切り替えにかかるサイクル数が増えちゃうからダメなのか、やっぱり)。
それは悲しいので、コンテキスト内多状態のように変換テーブルを使わないローカル制御部もつけた階層化バージョンも用意。
コンテキスト間遷移確率 (P) を下げる努力は合成の時にしなければならない。たとえば、ループを回るたびにスイッチしたりすると、それは大変。
JPEG decoder: P=0.3~0.5
Turbo / Viterbi decoder: P <= 0.0003
結構違うんだな。
所用サイクル数をはかると、仮想化だけより階層化をいれたほうが多いのだが、クロック周波数を考慮すると階層化したほうがよい。階層化まで入れた場合、仮想化なしとほとんど同じ実行時間になり、オーバーヘッドを抑えられる。
分岐予測やプリロードはこれから。
viterbi や turbo はだいたいひとつのコンテキストに入るからPが低いの? (ふ)
はい。だいたいコンテキスト内多状態で回ってます。
分岐がいっぱいあるようなものだと、コンテキスト内でがんばる、ということができないので、P は悪化する。
[ FPGAを用いた生化学シミュレータにおける入力ポート制約を考慮した演算パイプラインスケジューリング ]
もりりん。
スループットを上げたい、ということだけど、レイテンシを重視しているの? (梶原さん)
連立微分方程式なのでもげもげ。
レイテンシでなくて、後続ノード数でやっているのはどうなんですか?
レイテンシをクロック数でちゃんと数えてやると、自由度が下がっちゃってうまくいかないことがある。きちっと検証したわけではないが、ある程度自由度をもたせるためにこれでもいいのかも。
[ 複数のFPGAを用いた高性能流体解析システムの検討 ]
もりしー。
15桁一致でいいよ、というのはアプリケーション的に十分なの? (谷川先生)
倍精度でいいんだけど、このモジュールだけで評価するのはまだ不十分かな
斜め方向にするのに着目したのが性能向上の決め手? (jaist 佐藤先生)
そうですねー
[ リコンフィギャラブルプロセッサを用いた複数の拘束長に対応したビタビ復号器の設計と実装 ]
BER がどれくらいになったら拘束長をかえる、ということなら正解がわかってないといけないですよね? (泉先生)
うーん。訂正符号だから分かるのか??
送り側と受け側で拘束長の情報は共有しないといけないのでは? (柴田先生)
そういう設計になっています。
実際に使われている拘束長は? (黒田先生)
3から7くらいかが使われているんだけど、6以上はコンテキストに入りきらなかった。
全部パイプライン展開してる? ループくるくる? (泉先生)
いまのところ全部空間展開してます。
これ以上拘束長をのばしたりするとループになるが、損益分岐点みたいなのはかわる?
わかりません、、、
ゲノム微生物学会・発表メモとポスター
自分のポスター。わりと評判よかったです。
– IS とか transposon とか探せるかな? (transposon in transposon とか、泣きそう)
– contig を並べ直すときに近縁種と並べて使えないかな?
– ortholog 探すのに使える?
– draft sequence を読んだあとに速攻で使いたいぜ、というのが多いな。近縁種ゲノムに貼り付けるツールはあるはずなんだけど。
奈良女子大の佐伯先生が、さりげなくポスターで紹介してくださいました。


無重力状態ではバイオフィルムとかがどうなるのか、という研究。宇宙飛行士の健康とかを考えるとかなり重要だと思うのだが、アメリカなんかではそういう情報がけっこう機密扱いらしく、日本は日本でやらなきゃいけないのか。

GenomeMatcher. いろいろかわいい表示が出ます。負けてられません。

ゲノム微生物学会 Mar.08 / 産業微生物シンポジウム
[ 実用菌株を中心とした麹菌のゲノム進化の解析と醸造特性との関連について ]
Aspergillus は基本的に glucose と無機塩類があれば育つので、米麦大豆などとの共進化、みたいなのは特にないらしい。ゲノムは数 % の違い。
実際に、清酒と醤油を同じ菌でつくることもできるらしい。
でも、清酒と醤油では培地が違うし、自然に歴史のなかで用途によって適したものが使い分けられてきている、ということらしい。
毒素とかは 2/3 の株遺伝子群がで欠落しており、持っているものでも発現はしていない。
[ ゲノム解析に基づいた清酒酵母の醸造特性の解析 ]
清酒の香り成分などは酵母 (S. cerevisiae に似ている) によって作られる。
S. cerevisiae は一倍体だが、清酒酵母は通常二倍体 (一倍体でも増殖する) 。
低温でよく増殖する、生成酒の香味が優れている、諸味で高泡を形成する、ビオチン非要求性、などが特徴。

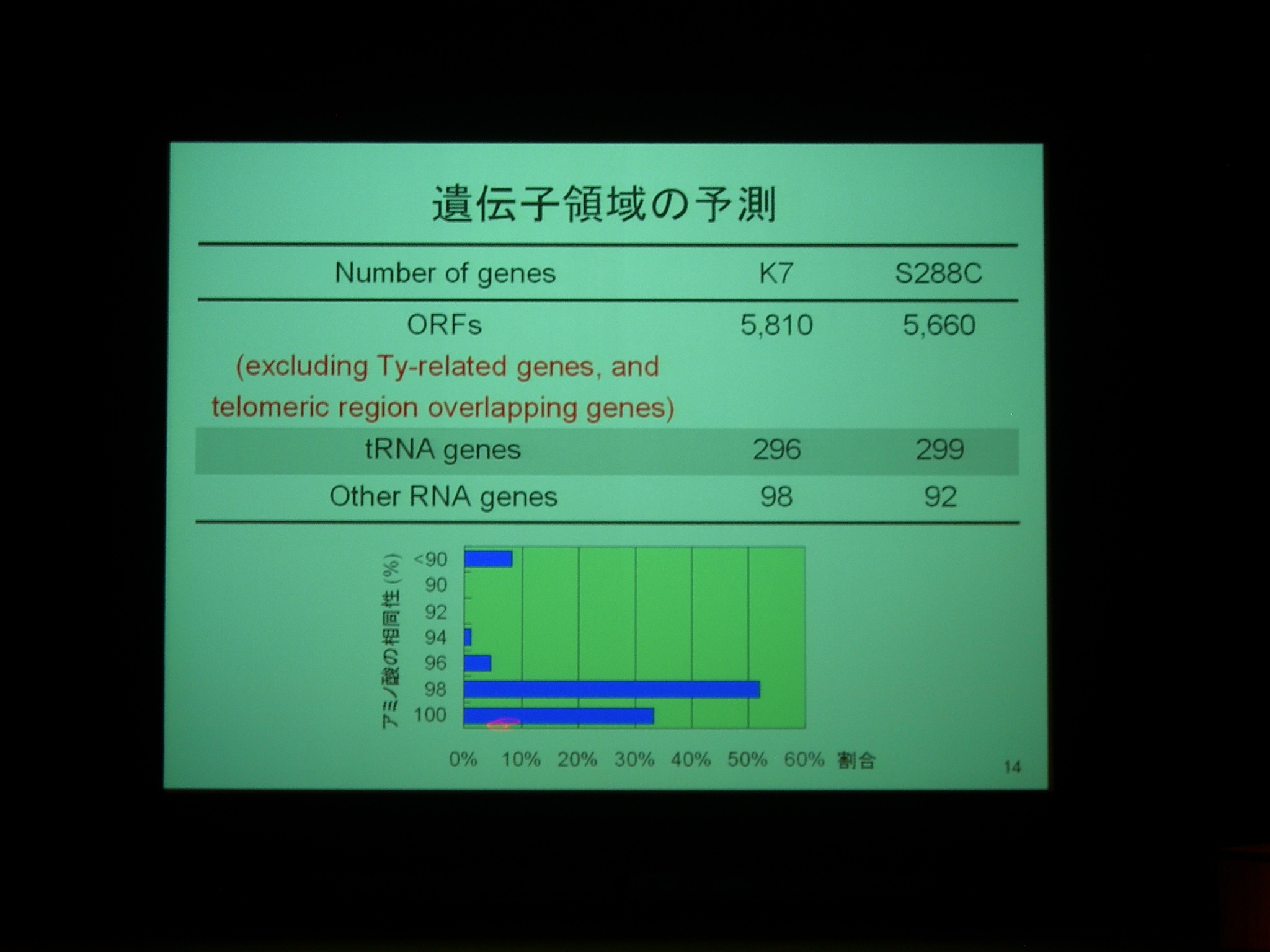
協会7号酵母のゲノムはほぼアセンブルが終わっている。実験室酵母とほぼ同じだが、いくつかの染色体で小さな逆位があったりする。
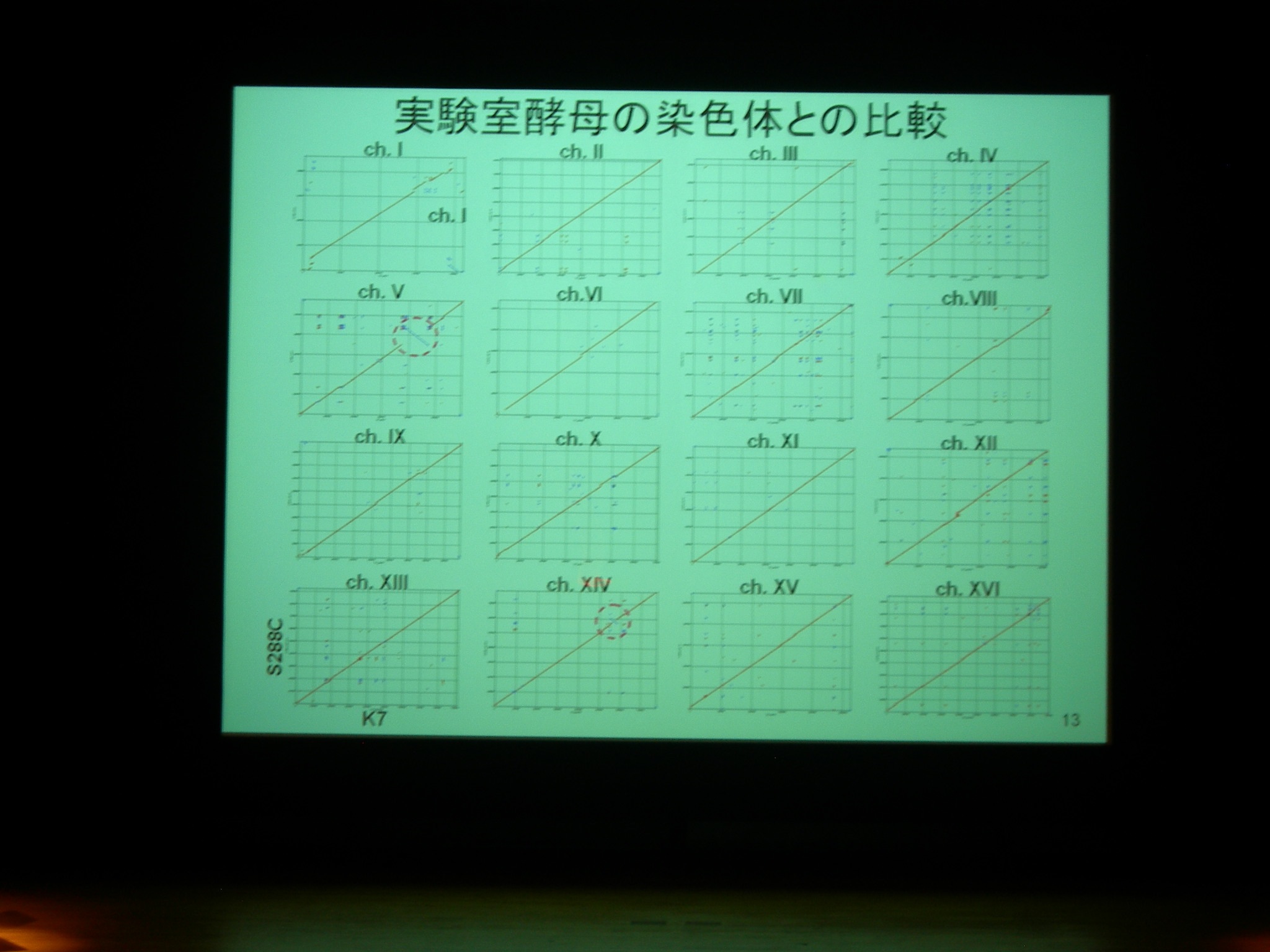
清酒酵母に特異的な遺伝子 (高泡を形成する遺伝子は AWA1 だ!) の多くは、染色体の両端に存在する。
実験室酵母にあって清酒酵母にない遺伝子やその逆は数えるほどしかない。
ビオチンを作る遺伝子 bio6 と bio1 がクラスタを形成し、4つの染色体の末端に存在。清酒・焼酎酵母だけがこれらを持っていて、ビオチンを合成する。


産業上重要な遺伝的形質の多くは量的形質。エタノール生産性とかね。これに関わる遺伝子座を調べるのが QTL analysis.
清酒酵母・実験室酵母それぞれ一倍体を交雑してヘテロ二倍体を作り、それで胞子分離一倍体を得る。これで醸造を行い、DNA マーカーで各種遺伝子の由来 (実験室酵母か醸造酵母か) を調べながら量的形質との関連を探る。


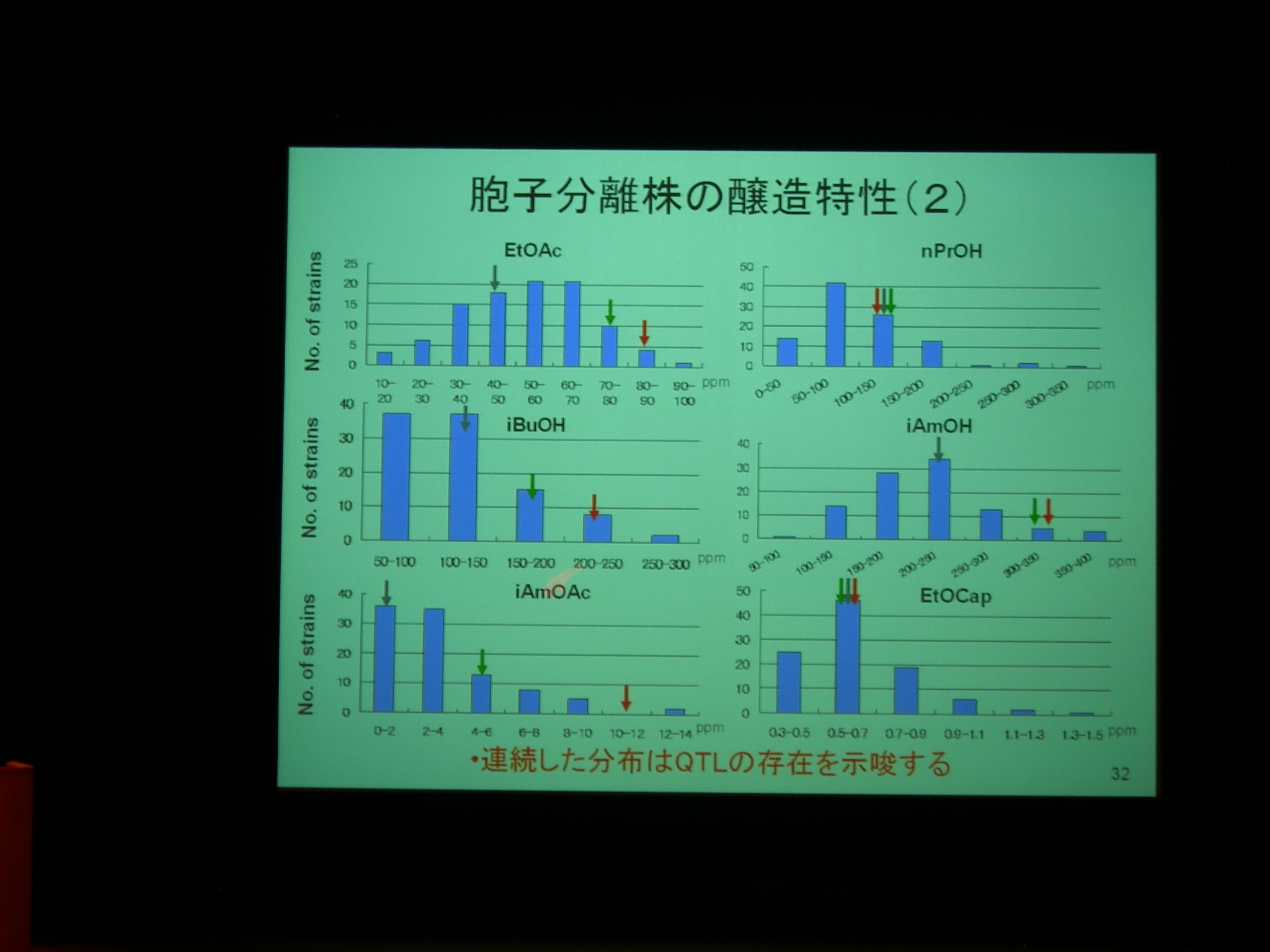

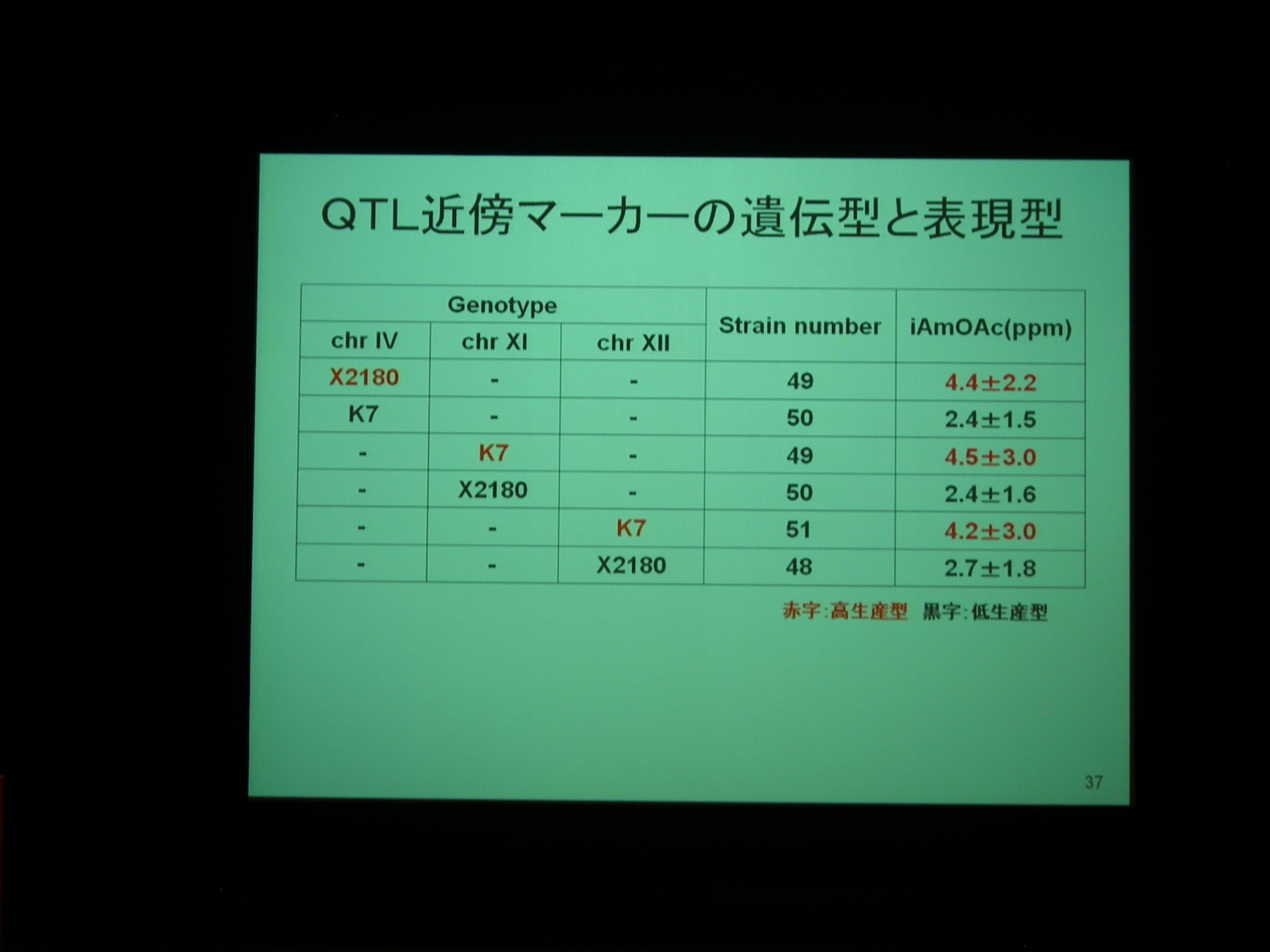
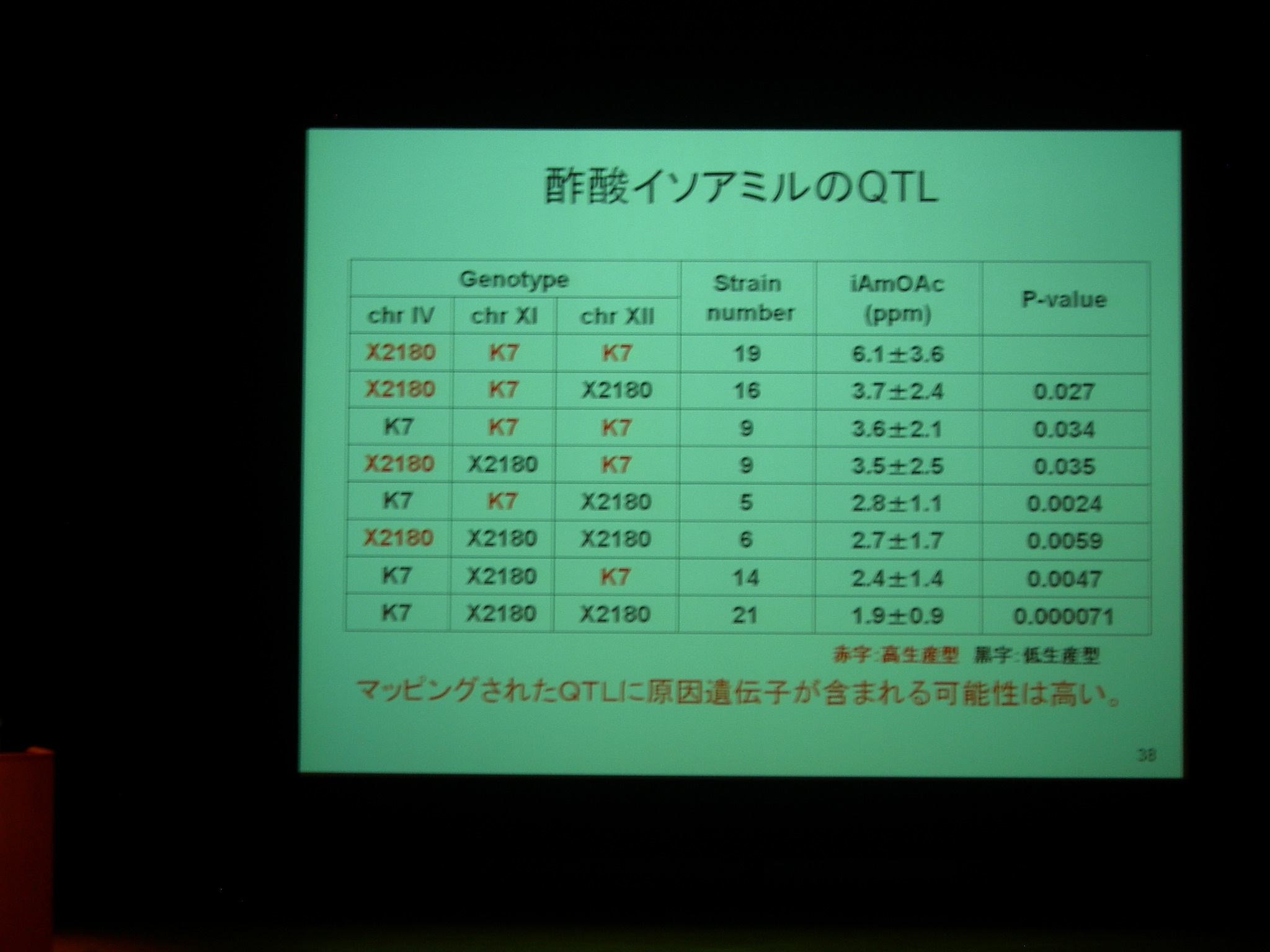
QTL 解析の結果、実験室酵母のほうが醸造酵母よりも生産性が高い物質もある → 改良の余地があることがわかる。
実験室酵母はずっとみんなが増やしているので、実際に飼っているものとの配列の違いが問題に問題になったりしない? → 遺伝子があるとかないとか、そういう大きな違いのところから始めているので問題ない。
[ 下面発酵酵母の減数分裂分離体を用いたQTL解析 ]
下面発酵酵母は S. cerevisiae ではなく、S. pastorianus.
ワイン酵母系の染色体と cerevisiae 系の染色体を両方もっているが、それらが交雑してしまうことはない。
完全長ゲノムはまだない。ビール大手3社がそれぞれドラフト配列を持っている状態。

QTL 解析をするには遺伝子マーカーを使うが、マーカーの数を増やせば解像度が上がる、というものではない。というのは、交配によってすべてのマーカー間の依存関係を完全に断ち切れるだけの個体を用意しなければならないから。ただ、死んじゃう胞子がけっこうあったりする上に、それをひとつひとつ genotype して発酵試験もしなければいけないので、とても大変。

実験の話が中心でよくわかりませんでした。すいません、、、
[ 地下生命圏におけるメタゲノム解析 ]
ODP: Ocean Drilling Program の掘削コア堆積物中に 1cc あたり 100,000 を超える!
地下生命圏は質量にして地球上の生命圏の 90% を占めるが、海底以下 100m をこえるとほとんどは死んでいたりする、静かな世界。
でも、プレート境界域とか、油田ガス田鉱山といった、水やエネルギーの流れのある場所ではそれに依存した活動的な生態系が生じる。
活動的地下生命圏は条件に依存した、わりと多様性の低い環境。それに対して、海底は非常に複雑。

菱刈金山:
30% が Archaea。16S rRNA の多様性は極めて低い。
末端配列から Bacteria / Archaea の判別がだいたいできることがわかったので、全ゲノム解析中。
ひとつの Archaea (HWCG I) についてはほぼ全長 (1.7M) が決まっている。
冷湧水域堆積物中における嫌気的メタン酸化群集の解析:
メタンハイドレートなど由来の高濃度メタンを含む海水で生きている連中。
メタン生成に関する遺伝子のほとんどすべてがメタゲノムライブラリから検出され、メタン酸化をメタン生成菌の逆反応でやっていることがわかった。すごいなー。
鉱山酸性排水バイオマット:
MS を使った初めてのコミュニティプロテオミクス。
微生物多様性の高い海底下生命圏への挑戦:
16S しかわからないやつとか、山のようにいる。
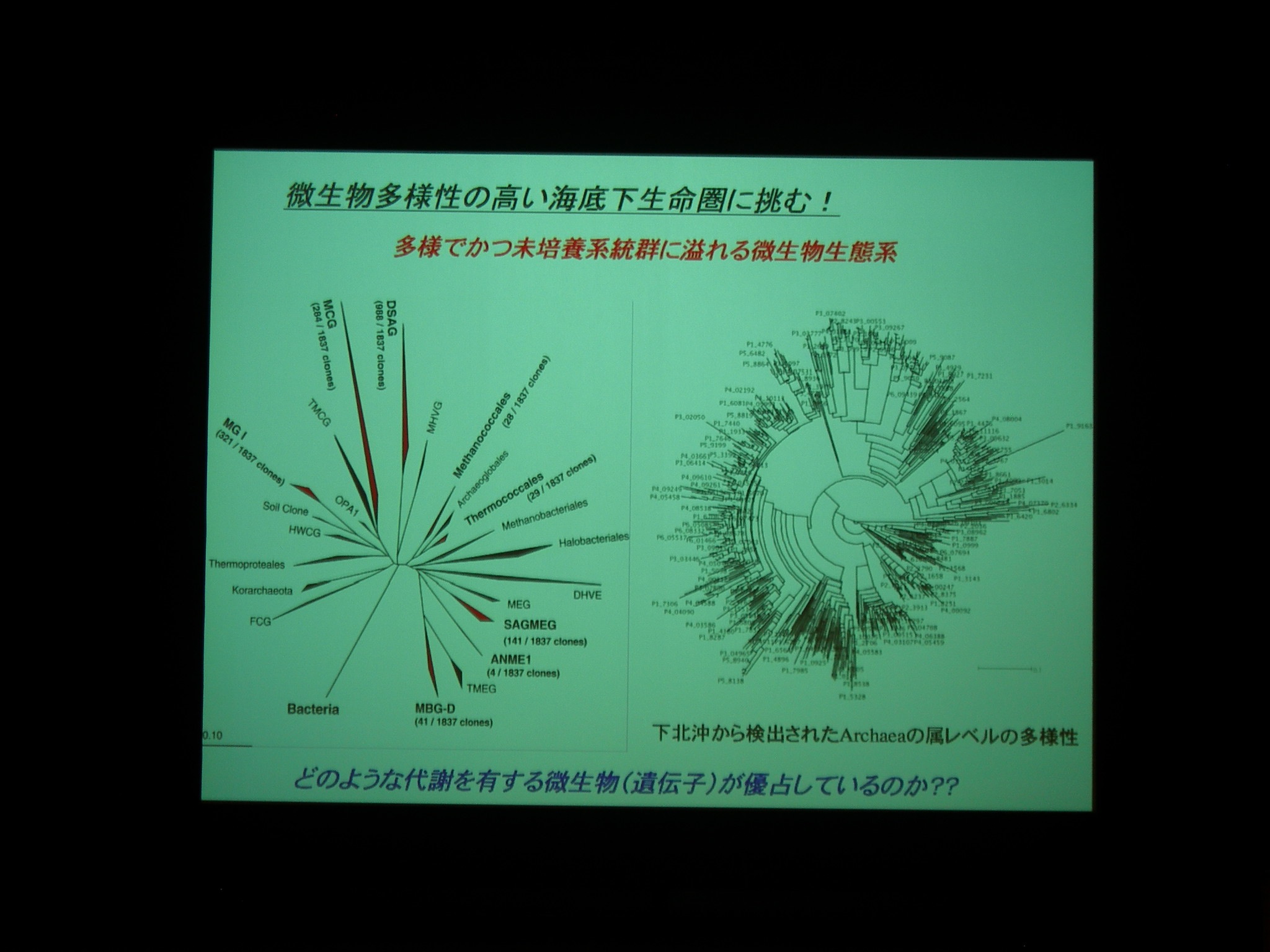
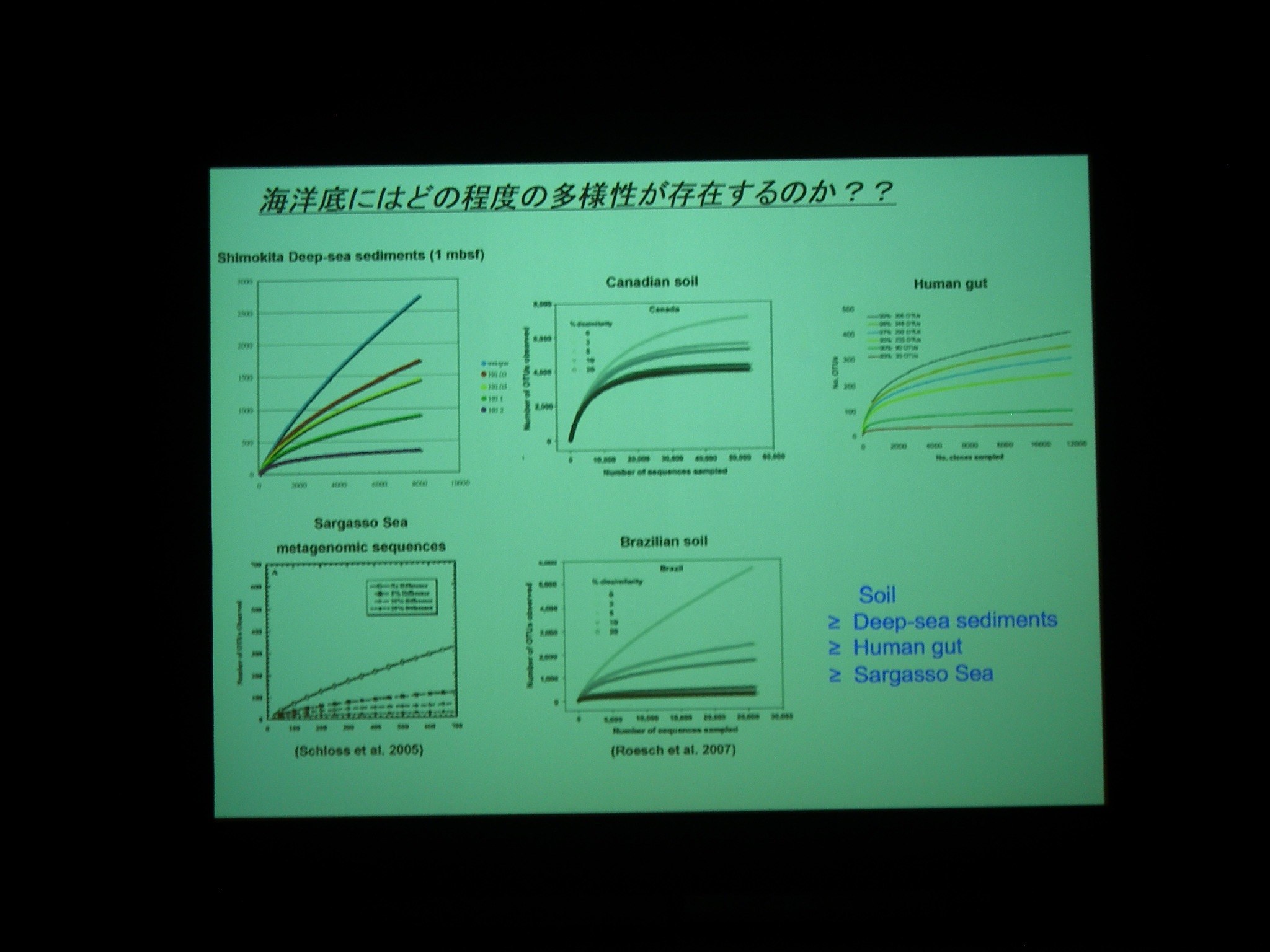
複雑さとしては、土壌 > 海底 > 腸内 > sargasso sea.
メタゲノムの問題は、基本的に数が多いやつのゲノムだけが見えちゃって「重要だけど少ない」連中のゲノムをとってくるにはものすごくお金がかかること。
これをなんとかしていくには single cell genomics が必要。培養しなくていいしね。
いい菌をとってきた、と思っても single cell genomics な時代だと、もう誰かが読んじゃっておいしいところをもっていかれているかも。これからは地球化学や微生物生態学と、いまゲノムとか応用微生物学をやってるひとが仲良くしないと欧米に勝てないぞ!
[ Lactobacillus brevis KB290のゲノム解析、および抗生物質耐性試験 ]
KB290: 京都の漬物「すぐき」から分離した。
すぐれた耐酸性があり、腸内への到達性が高い。
安全性評価のためにゲノムを解読。109 contigs, 2.4Mbp.
病原因子がないか (日和見感染とかがないか)?
– no virulence gene at cutoff of 10^-10
– 安全性調査のためのデータベース: MvirDB
薬剤耐性がないか (他の菌にうつるおそれがあるので)?
– 欧州にはそういうガイドラインがある
– vancomycin, tetracycline, ciprofloxacin への耐性がガイドラインの数倍。でも、本当にヤバい菌は基準値の 100 倍とかになるらしい!!
– 基準値を超えているので、接合伝達試験をして、他の菌に移るかどうかを試す。相手は E. feaecalis FA2-2 (腸球菌かな?) 問題なかった。
– 既知の耐性遺伝子が存在しないことも確認した。欧州の基準ではその他の耐性遺伝子がないことを確認することも求めており、それもクリア。
– point mutation でものすごく耐性がでることがあるので、そういうのもチェック。
など。とりあえず安全そう。テストって大変だなー。みんなやってるの??

マウスや人でのテストも問題なし。というか、既にみんな食べているやつなわけで。
腸管への付着性も評価。
腸管付着因子として知られているタンパク質がどれくらいあるかを調べたが、
残念ながら実験の結果も検索の結果も、あまり高くない。
ゲノムでテストをしたほうがコストとかのメリットがある? → もともと食べられていたものなので、最初にマウスとかでやる必要はなかった。ゲノムによる情報も実験と同じくらい重要で効果的であると考えている。動物実験は外部に委託するので、数千万円というお金がかかり、ゲノム解析の方が安い部分もある。
Lactobacillus の病原性としてはどのようなものが考えられる? → DB にあるのは薬剤耐性の translocation。
Translocation は host が病的な状態であるときに問題になることがあり、動物実験をしないといけない部分がある。
ゲノム微生物学会 Mar.08 / oral session 7
応用ゲノム。
[ 38: 塩類集積環境の重金属浄化に有用なセルフクローニング型アーミング Halomonas elongataの作製 ]
塩性化・アルカリ化・重金属の濃縮などが同時に起こる場合の浄化。
H. elongata は金属結合ドメインをもっており、それを外膜リポタンパク質にくっつけることで、細胞表層に呈示するようにする。
外来遺伝子を導入せずに、相同組み替えだけで実現。
1. 高塩濃度条件 (3% NaCl, 18% NaCl) で安定して機能する外膜リポタンパクの選定。
2. 高発現させたときに細胞が凝集しないものをえらぶ
3. そのリポタンパクが欠失しても (これから機能を変えちゃうので) 塩ストレスで死滅したりしないかを確認
Cu 選択的な浄化能を示すものができた。
ドメインを多重化することで、さらにパワーアップ!
[ 39: 枯草菌ゲノム縮小株のトランスクリプトーム解析 ]
枯草菌の高いタンパク質分泌能力と、容易な操作性は工業用途にも便利。
だけど、ストレス反応みたいな、いらない機能もあるわけで、それらを削除することで、物質生産に特化したものをつくりたい。
先行研究で、7.7kbp の外来性遺伝子領域を削除したり、必須遺伝子を同定した研究はあるが、生産性向上に寄与したかどうかの評価はない。

874kbp を削除し、セルラーゼ・プロテアーゼの活性を 200% 向上させることに成功。増殖は若干遅いが、定常期においても高い生産性を維持している。
胞子形成に至るシグマ因子の発現は遅れている?


削減株が培養後期でも活発ということは、後期での viability が低下することにならない? → CO2 排出量が減っていないんで、よさそう。
成長をとめて増殖の準備をしようとするところがなくなる、と思うのですが → 後期の細胞の維持もちゃんとやっていそう。溶菌に関するところは削除されている。
セルラーゼ・プロテアーゼ以外の生産性向上については? → 分泌が律速になってあがらないもの (アミラーゼなど) があることもあるが、そこをいじってやれば何とかなると思う。
[ 40: DNAマイクロアレイデータ解析に基づいたエタノールストレス耐性を示す酵母菌株の創製 ]
実験室酵母と、ストレス耐性を有する醸造酵母(協会7号: IFO2347) の違いは?
ストレス耐性遺伝子の発現はエタノール添加前後で違う?

ストレス耐性遺伝子は、なにもない状態でも醸造酵母のほうがたくさん発現している。
実験室酵母でも、tryptophan の取り込みに関わる遺伝子と、培地への tryptophan 添加でエタノール耐性が出る。
実験室酵母が1倍体で協会7号が2倍体なのはどうかと・・・→ すみません、いろいろありまして。
そうか、酵母菌って2倍体もいるのよね。たいへんだ。
[ 41: 乳酸耐性酵母の分子育種工学 -欠失により乳酸感受性を付与する出芽酵母遺伝子の網羅的同定と機能解析- ]
ポリ乳酸がプラスチックとして注目されており、その原料の乳酸を生産させるのに出芽酵母が注目されている。乳酸耐性をうまくもたせることができれば、中和処理なしで大量生産ができるようになる!
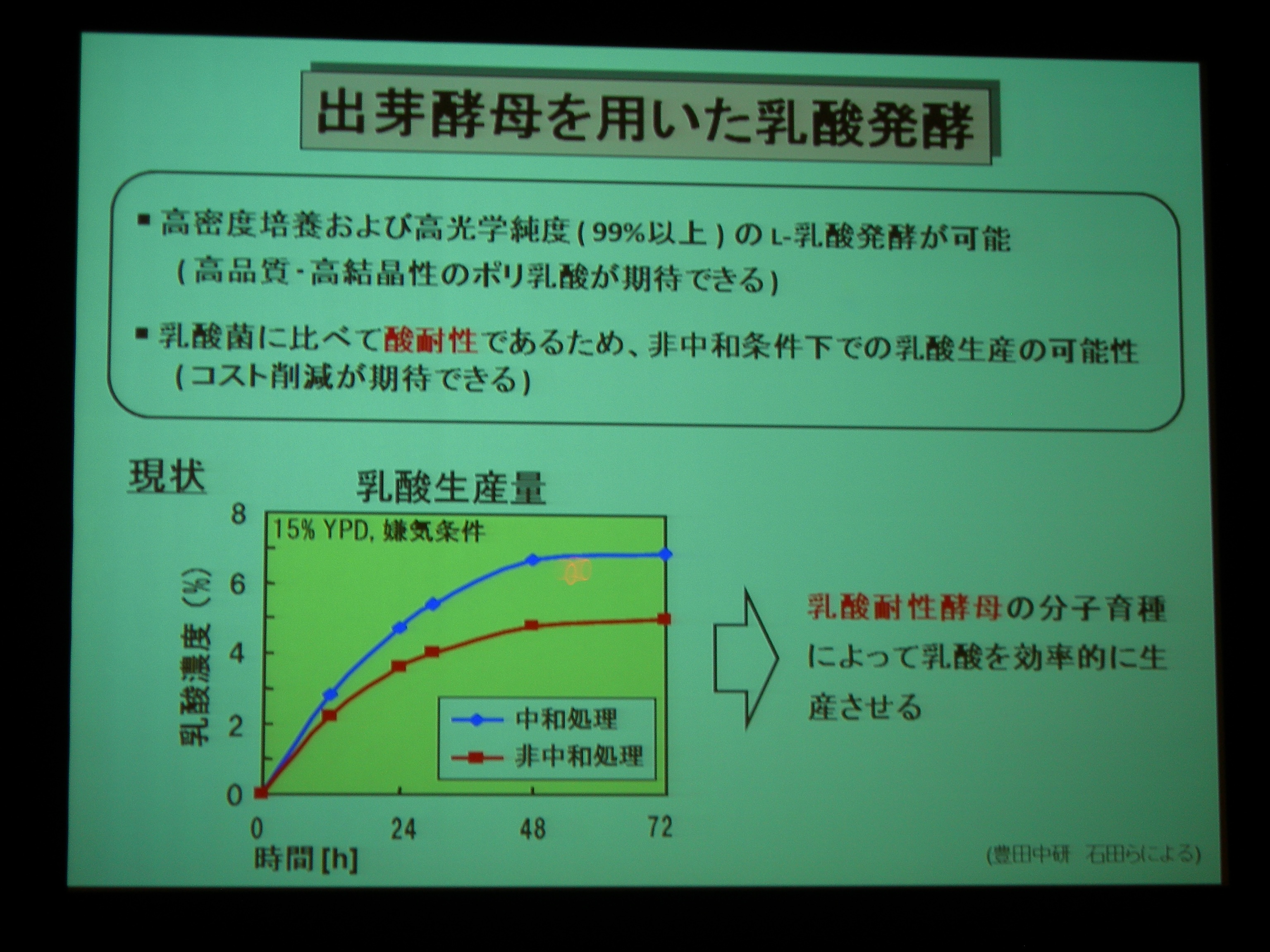
乳酸耐性には液胞や細胞内輸送に関係する遺伝子が重要。
– 破壊でも乳酸耐性を引き起こすことができる
– 多コピーで乳酸耐性を得ることもできる。ストレス応答などの遺伝子をプラスミドにいれて overexpression することで乳酸耐性化。安定して動かすために、染色体上で高発現プロモーターとくっつけて成功。
[ 42: カンジダ酵母における病原性ゲノム機能学(網羅的遺伝子発現制御株の構築と応用) ]
S. Ce の必須遺伝子群との ortholog をもとに、必須遺伝子群を同定。800-1000遺伝子くらい?
Tet 株を使っている。マウスに感染させたあとで、飲み水で発現を制御できるので便利。
これをもとに高真菌薬をつくりたい。必須遺伝子群のなかで、ヒトには存在しないものを標的にすることで薬効が高く、副作用の少ないものを狙う。病原真菌に高く保存されている遺伝子に絞り込むことで広い範囲に効くようにもしたい。
5,300 genes / 150 screened in silico / 10 genes in vitro 。実験頑張ってます。ほんとは10個じゃなくて、もうすこしやりたいですが・・・
抗真菌ペプチド医薬。ペプチドを環状化することで安定化させたい。インシリコで分子進化させたものをいくつか実際につくって、テストしている。
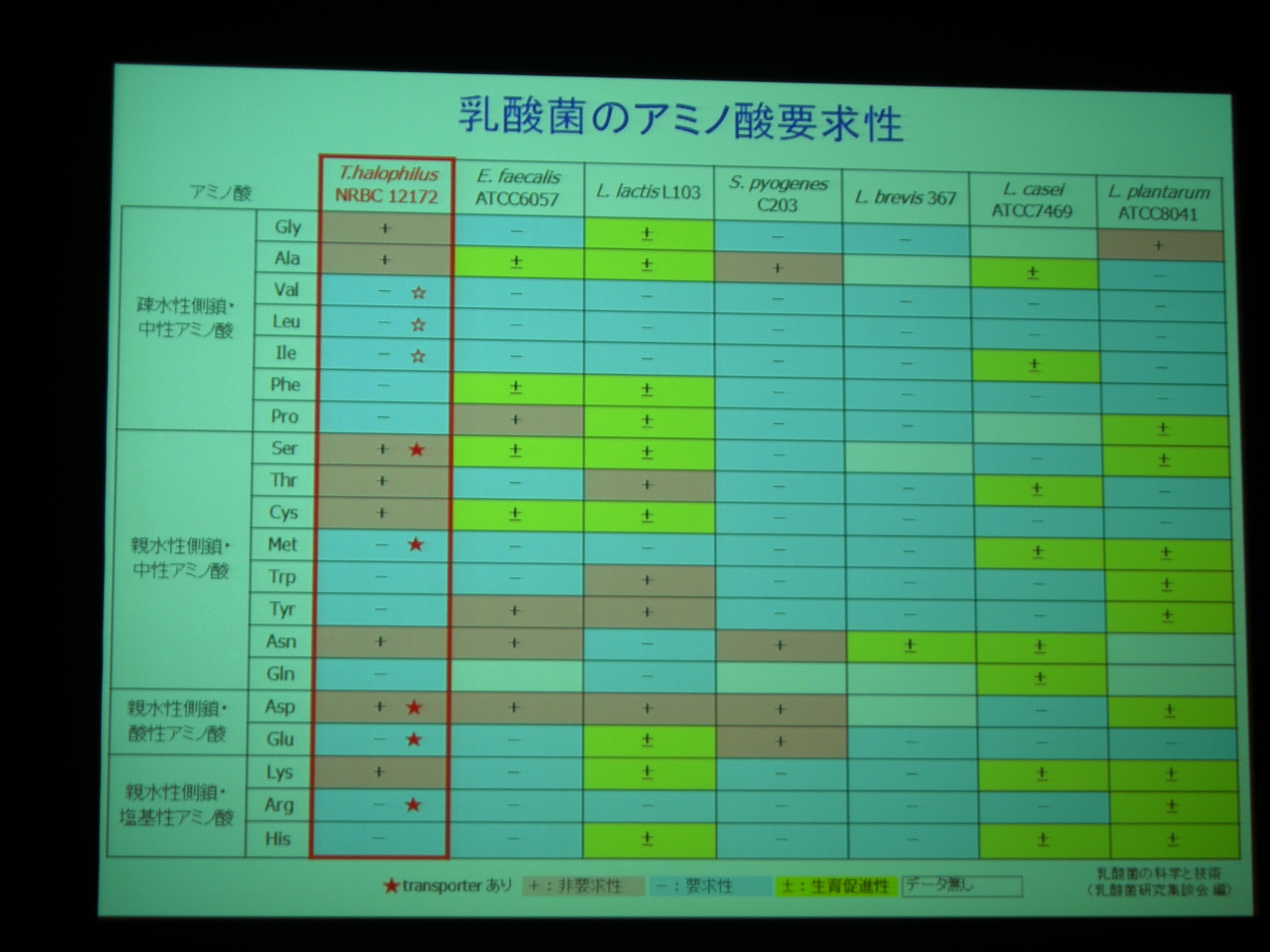
[ 43: 醤油乳酸菌Tetragenococcus halophilus NBRC 12172株のゲノム解析 ]
IS が多くて、他の乳酸菌と比べるとゲノム構造はあまり保存されていない。
でも、COG 分類を眺めると、遺伝子は大差ないことがわかる。
TCA サイクルは一部が欠けている、アミノ酸合成系の一部が欠けている、といった特徴。これはほかの乳酸菌とかわらない。
大事なのは塩耐性。
Choline → Glycine betaine の合成系や Na / K の排出 / 取り込み機構 が重要な重要っぽい。
Na 輸送に際して ATP を作れる! これも塩耐性に貢献しているはず。
ほかの耐塩性乳酸菌とはくらべた? → ほかのゲノムが公開されたばかりなので、まだ比べていない。