[ 光再構成型ゲートアレイにおける MEMS アドレッシング技術 ]
レーザーをたくさん用意する代わりに DMD で反射させたレーザーをホログラムメモリに照射する。これはものすごくたくさん (億オーダー) のコンテキスト数を持たせるために必要。
[ COGRE: 面積削減を目的とした少構成メモリ論理セルアーキテクチャ ]
よく使う論理関数をプロファイリングして、LUT じゃない最適化された論理セルを作る。
論理セル数は減るんだけど、配線が増加するのが問題。
面積は論理合成ツールのところで評価しており、レイアウトした結果ではない。
[ An Error Detect and Correct Circuit Based Fault-tolerant Reconfigurable Logic Device ]
– mitigates up to 2bits SEUs
– on the fly scrubbing
– EDC has 6.8-10 times dependable than a tile level TMR structure
is EDC for only COGRE?
LUTにも使える。but COGRE has less memory, so it’s more effective.
MTBF はどうやって計算している?
Xilinx が発表している SEU 頻度についてのデータがある。10^6 秒 (時間) で何ビット壊れる、みたいな。
[同期/非同期ハイブリッドアーキテクチャに基づく低消費電力FPGAの構成]
非同期回路は動いてないときは電力食わないけど、動くとたくさん使う。なので、動作状況に合わせて同期回路と組み合わせることで電力を最適化することができる。
ふつうの island style FPGA なんだけど、logic block に同期モード・非同期モードがある。ただ、ブロックがでかくなっちゃうんだけど・・・
非同期のところは ack を返す必要があるわけだけど、それは LB ごとに handshake して ack 返すの?それだと細かすぎませんか → いまのところは。本当は何ステージかまとめて handshake できるようにしたいのです。
非同期と同期の連動のためには FIFO があちこちに入っているらしい。
リークはどうせ非同期でもあるわけで、そうすると使用面積が問題になるから、そこまで考慮したほうがいいのでは → 考慮してます。
[マルチコンテキスト型動的リコンフィギャラブルプロセッサからコンテキストメモリをなくす方法の提案]
えええええ?
コンテキストメモリをやめてレジスタに置き換える。
コンテキストの実行時間をなるべく長くする+コンテキスト情報の流し込みを高速化する。
Loop unrolling に似ているけどちょっと違う方法 (LSKD) というのを提案してみた。
これでコンテキストあたりの実行 (滞在) 時間を長くするんだけど、コンパイラによる変換だけではだめで、ループカウンタとかそういう付加ハードウェアが必要。
流し込み高速化にはマルチキャスト(ROw MULTIcast Configuration) とか差分再構成とか。
実行時間はループ依存性にもよるが、13〜18% くらい増える。実行時間増大の抑制には差分再構成が有効。
面積と電力はがっつり (60%くらい削減!) 減る。
いまのところループの変換は手作業でやってるのでコンパイラへの組み込みが問題。
コンテキストあたりの滞在時間を増やす手法は既存の MuCCRA でも使える?→ Yes
バスでガンガン送り込むのはけっこう電力食うのでは?→意外とそうでもない。
LSKD 使うと中間結果をとっておかないといけないので、実は configuration memory が減った分 data memory が増えていたり… → おっしゃるとおりなのですが、もともとあったレジスタを使っているので、まあ、それほどずるくはないかな。
[再構成回数削減による動的リコンフィギャラブルプロセッサの消費電力削減手法の提案]
同じ処理をコンテキスト切り替えの際の再構成あり・なしでやってみたら、だいぶ電力が違う。
そうすると、コンテキストが切り替わってもなるべく再構成される PE が少なくするようにすると消費電力を抑えることができるんではないかと考えた。なるほどー
いろんな種類の演算器をごちゃっと並べておくことになる場合があり、そうすると RoMultiC と相性が悪くて構成情報が大きくなったりする。性能の低下は原理的に発生しない。
性能が低下しない、ということだがデータパスがややこしくなって配線遅延が増えたり配線不能になる、ということはない? → 今回は発生していないが、考えられる。
[SIMD/MIMD動的切り替え型プロセッサIMAPCAR2の性能評価]
画像認識 ASSP.
プロセッサからみた画像処理の特徴:
– 最初は候補領域の検出: 全体をスキャンするので、データ並列性が高い。SIMD がいいかな。
– 次は候補領域の検定: こっちは MIMD のほうがいいかな?
SIMD の各 PE が独立したメモリを持っている。
4つの SIMD PE のハード資源を浸かってひとつの MIMD PU + FPU に再構成できる!
SIMD-MIMD 切り替えのペナルティは? → 全員キャッシュミスの状態になる。なるべくそれを緩和するために全員にデータを配るとか、そういう仕組みを用意しているが、プログラムで対応しないといけない。
[FPGA上のArbiter PUFの定量的評価]
Trojan Hardware!
安全に回路を構成するにはどうしたらいい?
PUF = Physical Unclonable Function.
製造時に制御できない物理的特徴でデバイス固有の値を出力。光の拡散具合とか。
半導体のばらつきを利用した PUF はどうよ?どうやって評価したらいい?
というわけで、45個の Virtex-5 で arbiter PUF のテストをしてみた。
arbiter PUF: 長いセレクタのチェーンを構成して、信号の遅延差を測る。
ring oscillator PUF: リングオシレータをふたつ作って、周波数の違いを測る。
[ Scalable Core 2.0 ]
XC3S1200E 搭載。裏側の基板がなくなりました。
裏側の基板がなくなったので、隣接する FPGA との接続配線長が短縮。
カテゴリー: Conference Logs
RECONF @ Shizuoka: Sep.16, 2010
高山からばびゅーんと移動してきました。
渡邊先生招待講演。
[ プロセッサを作りましょう ]
MISC (Mono-Instruction Set Computer): 単一機能のプロセッサ (RISC でも CISCでも) を作りましょう。
昔は CISC。メモリは大切だからちょっとの命令でいろいろやりましょう。
今は RISC。メモリはたくさん使えるから命令の直交性を重視してぶいぶい回しましょう。
FPGA にも MicroBlaze とか NIOS が載り、ちょっとだけユーザ定義の命令もつけられるけど、これはいままでのプロセッサ (CISC/RISC) の延長。
RISC は CISC より効率がいいけど、それでも回路のどこかは idle になってる。もったいない。そこで MISC です。シリコンの上に載っている ALU はいつも一種類! (やべえ、かっこいい)
でも、これをやるには高速な再構成が必要なので、そこで光再構成+ホログラム。
問題はレーザーアレイなんだけど、面実装のレーザーアレイで 256×256 のとかがある (surface emitting laser array ってやつ?)。
いま実験システムには 4×4=16 のレーザーアレイが実装されていて動いている。
[ 宇宙でも使いましょう (ARC2010) ]
FPGA は RAM のかたまりなので、宇宙で使うのはたいへんで、ECC を使ってたまに再構成しなおしたりしてやる必要あり。
一方で、ホログラムメモリは放射線にはめっぽう強い。冗長性もあるから、宇宙でホログラムを書き直す時に多少壊れた configuration data が届いたとしても問題ない。
ホログラムに光をあけたときに明点ができるのは、ホログラムの透明部分を通じた光の位相が揃ったところ。なので、多少ぶっ壊れても OK。位相が揃ったところ、ということはつまり、光で多数決をしているようなものですね。
ホログラムメモリを emulate するのに MEMS mirror (DMD) とか使える。プロジェクタとかに入ってるやつなら 1024×768 くらいの解像度も出るし。それで、20% くらいのノイズを入れてもちゃんと再構成できる。
[ ビジョンチップ (FPL2010) ]
現在のイメージセンサは 30fps のが多い。だけど本気で人間を超える何かをやろうとするなら 1000fps くらい必要。
Analog vision chip というのもあって、それだと高速に平滑化とかエッジ検出とかできる。だけど、それでは画像認識には持っていけない。
デジタルだと解像度を稼ぐのは結構たいへんで、どうしても SIMD プロセッサアレイとかにせざるを得ないし、メモリをたくさんばらまけないので、テンプレートマッチングのためのテンプレートとか、そういうものを入れておくことができない。
そこで、光再構成アレイにビームスプリッタを入れて、構成情報と一緒に画像情報を入れることができるのではないか?メモリを増やすことはできないけど、テンプレート画像をホログラムに大量に入れておけば、それを超高速に流し込みながらマッチング処理を行うことができる。
[ 質疑 ]
ホログラムメモリそのものを LUT みたいにして計算処理につかえない (佐野先生) ?
光コンピュータのひとがやってます。問題はそれだけのデータを突っ込めるホログラムの構成材料。
再構成時間はつまり命令フェッチにかかる時間なわけですが、その改善の見込みは (井口先生) ?
ホログラムメモリの光エネルギ効率が悪い。液晶だし。
瞬間的に高出力が出せるようなレーザーがあるといいかも。
SPD も問題で、いまは standard cell で作っているので、それがしんどい。
HEART 2010
accept ratio was 54%.
[[ Session 1: FPGA-based Applications ]]
[ Implementation and Evaluation of an Arithmetic Pipeline on FLOPS-2D: Multi-FPGA system ]
最初のひとがいなくていきなりわしら。
精度を変えることは考えた? → double precision が minimum requirement なので。
IFC と g95 で4倍速度が違うのはなぜ? → SSEとか使っているかも。dualcore?
発表おつかれさまでした。
[ Efficient Reconfigurable Design for Pricing Asian Options ]
Stochastic simulation (single precision) on XC5VLX330T @ 200MHz, 34W.
– 313x Xeon quad-core, 80W
– 2.2x Tesla C1060, 200W
[ An FPGA-based fast classifier with high generalization property ]
Cyclone vs Stratix vs Athlon. Power, cost, performance.
DSP unit は使った? → 使ってない。LUT で全部つくるのが natural だと思う。
Combinational circuit だけで、pipeline にはなっていない。
Scaling とかは? → future work です。
[[ Session 2: Frameworks ]]
[Dynamic Vectorization in the E2 Dynamic Multicore Architecture]
Microsoft はプロセッサアーキテクチャもやっているのか・・・
32cores per chip.
全部のコアが single precision FP を持っている。power gating とか。
[Binary acceleration using coarse-grained reconfigurable architecture]
How many bits for configuration → basically instruction. 20bits.
[Implementation of a Programming Environment with a Multithread Model for Reconfigurable Systems]
SRC-6. やっぱ僕も streaming DMA とか実装しないとダメかね。むー
レジスタへのアクセスはどうやって検出するの? → Carteでは基本的に変数がレジスタで、オンボードメモリへのアクセスには特別な記述が必要。
[Runtime Multitasking Support on Reconfigurable Accelerators]
profiler の結果に基づいてごりごり。dso (dlopen()) を使って実装している。かっこいー
[Programming Framework for Clusters with Heterogeneous Accelerators]
Luk先生直々にご発表。
(Phenom X4 + Tesla + V5LX330T) x 16
[[ Session 3: Accelerators ]]
[An efficient CELL library for Lattice Quantum Chromodynamics]
double precision が必要だといったけど double でやっているの? → yes. penaltyがあるよ。
[Software-based predication for AMD GPUs]
GPU では control flow とかのペナルティが大きいので、ALU packing したり分岐とかの予測(というか、control flow clause の統合) をやっといて性能を上げましょう的なお話。10% とか、すごいのだと 50% くらいの効果がある。
[Multipliers for Floating-Point Double Precision and Beyond on FPGAs]
多倍長な乗算で DSP block の使用量を抑えたい。DSP48E は 18x25bit の非対称構成。これを使って、部分積をうまく詰め込む: Automated tiling.
Logicore の FP multiplier より DSP block の数が減って、しかも速かったりする。これはかっこいい。
[Prototype Implementation of Array-Processor Extensible over Multiple FPGAs for Scalable Stencil Computation]
佐野先生のところの、GALS array の話。
jitter とかから必要な FIFO の深さは estimate できる? → 6段くらい。
[[ Invited talk 2: Custom Computing for Efficient Acceleration of HPC Kernels ]]
Bandwidth と arithmetic performance のバランスが大事!
– Custom computing で解決しましょう
– Roofline: an insightful visual performance model for multicore architectures が紹介されてた。面白そう。あとで読もう。
– Real time data compression to get more bandwidth.
– cubic predictor を使って、CFD で 4x bandwidth とか出している。これはデータの中身によるからなんともいえないけど、頑張ってやってみる価値はあるな。
31bit の custom FP format を使っているのはどうして? → fraction を1ビット削ったIEEE754.
RECONF研 (May.14, 2010)
[FPGAを用いた様々な大きさ、回転角を持つパターンの検出手法の検討]
梶原さん: 回転のところで、隣のピクセルに移動しちゃったところだけを計算して処理量を減らしているんだけど、大きな画像になるとあまり節約にならないのでは?
鈴木さん: いま使っているFPGAでできるサイズの画像ではこれでよいと思っている。大きいのでは違うけれど。
[振動抑制を考慮した追従システムのFPGAによる実装]
現代制御なアルゴリズムをMATLAB/Simulink のモデルから実装。
組み込みなソフトウェアに対してどれくらいのアドバンテージがあるか?
Xilinx, Altera などのツールはあるけど、主に DSP 用であり、FPGA 用の機種依存なブロックを使ってやらないといけない。Mathworks が出しているツールは限定的だが標準のブロックをサポートしている。
制震制御: たとえば水の入ったコップを、水をこぼさずに高速に移動する。
鋳造のラインとかで使う。装置の制約 (最大速度、最大加速度など) を満たすために、リアルタイムでシミュレーションしながら次の動作を決める (予測制御) 必要があり、計算が大変で、Atom Z530 では実時間制御に間に合わない!
ソフトウェア実行版とHDL版ではMATLABのレベルで書き方を変えないとダメ。
京さん: 組み込みで速いプロセッサを使えないのはなぜ?
市川先生: コストとか、あるいは他機種と共通部品だったりするので。高速な予測制御はソフトウェアではできないので、コストが許すならばFPGAなどを導入することで、いままでできなかったことができるようになる。今回は、ふつうの市販のツールでどれくらいのものができるかに興味があった。
[SIMD型並列度可変プロセッサコアの提案とその検証]
Super H-2互換ソフトIP の Aquarius (available at opencores.org) の Verilog 記述を使用。
マルチコアにするよりはSIMDのほうが省面積な感じで、SIMD のほうが、使用 LUT に比例して素直に性能が伸びる。
柴田先生: 演算器とレジスタはセットにして並べるの?
田邊さん: はい。
柴田先生: 開発環境はどうしていますか?
田邊さん: SSE用の開発環境とかの出力を translate することを考えています。
渡邊先生: オリジナルの命令セットに対してどういったSIMD命令を追加していますか?
田邊さん: 実は命令は追加していなくて、すべての演算器が同じ命令を実行するようになっている。演算ユニット間のネットワークができてから、通信関係のことを考えたい。
[PC-FPGA複合クラスタにおけるソフトウェア-ハードウェア間通信と遠隔呼び出し]
PCクラスタ用ネットワークにおけるFPGAの利用はMaestro2 (筑波大) とか DIMMnet (慶應)とかに見られるし、計算にも使われている。
井口先生: なんか遅いのは、実は測定タイマの関数の精度の問題では?もっといい性能が出ているかも :p
小畑先生: そうかもしれません 🙂
梶原さん: FPGA から PC を呼ぶ、という処理ができるようになっているけど、どう使う?対称性があるのはいいけれど。
小畑先生: ちょっと検討します。
[複数FPGA上で動作するスケーラブルアレイプロセッサのためのGALS設計]
ステンシル計算とかをするための、globally async, locally sync なシステム。
FPGA ボードを複数使って検証。ストールの解決メカニズムがキモで、かなりうまくいっている。
小栗先生: dual port FIFO を使うとデータはうまくいくんだけど、handshake のところはむずかしいので、気をつけて作らないとmetastableに落ちて誤動作が起きることがあるので、複数のクロックを使うと難しいかも。
そうか・・・難しいなあ。
[複数の異なるアプリケーションを用いたFPGAベース・リコンフィギュラブルシステム用OSの性能評価]
ホスト PC にくっついた FPGA なんかで、複数の SW task が動くのは当然として、それに対応する複数の HW task を動かせるような OS 的なシステムを作っている。プロトタイプは SPARTAN3 を4つ搭載。
渡邊先生: HW task は1アプリケーションでFPGAひとつ?
児島先生: 再構成の事情とかでそうなっていますが、将来は何とかしたい。
[An Efficient Implementation of Exhaustive Verification of the Collatz Conjecture using DSP48E blocks of Xilinx Virtex-5 FPGAs]
専門委員会があって遅刻しましたごめんなさい。
市川先生と小栗先生がこれって何で証明できないのか、という議論で盛り上がる。
Virtex-II のときからの性能向上には DSP block の寄与が大きいとのこと。
[マルチFPGAプラットフォームFLOPS-2Dにおける演算パイプラインの実装]
ちょっと導入のスライドがまずかったなー。preliminary work だっていうのを前面に出さないと誤解される、ということがよくわかった。やってる内容は悪くないと思う。
[動的再構成デバイスによるリアルタイム翻訳システムの構築と検証]
DAP/DNA2!
RECONF研 (May 13, 2010)
[FPGAを用いたDC-DCコンバータ向け高速比例ディジタルPID制御方式の実装]
長崎大の浜脇さん@柴田研。
50MHz の FPGA でクロックの位相をずらして 100MHz, 200MHz での PWM.
PID の P 要素だけサンプリングレートを上げて精度をよくすることができた。
名古屋先生: DC-DC コンバータの精度が上がるのはわかった。効率にはどう貢献する?
浜脇さん: 制御回路の消費電力がそれほど大きくならないとわかった。
柴田先生: 負荷の急激な変動にうまく追従して余分な電力消費を減らしましょう、という趣旨なので、精度が上がることはちゃんと意義があります。
泉先生: 2.5ms くらい応答時間がかかるようですが、データセンターではそれで充分?
柴田先生: 負荷モデルは別に検討チームがありますが、2.5ms よりはもうすこし頑張った方がいいかもしれません。
[FPGAを用いた全探索法による可変ブロックサイズ動き予測の実現]
丸山研の学生さんの発表。
+-32pixel, 30fps で、DVDサイズの探索を実現。
+-64pixel になれば、HD対応です。その場合回路規模は16倍。
Virtex-5 で実装。BlockRAM ごりごり。スキャン方向を工夫することでメモリを旨く使っている。
オフチップのメモリもちゃんと使います。
[FPGAを用いたCLAHEの実時間処理の実現]
丸山先生が代理でご発表。
コントラスト強調で暗い部分なんかをきれいに見えるようにするが、ノイズやハイライトをうまく取り扱えるようにする (局所的コントラスト強調)。
ヒストグラム伸長よりもヒストグラム平均化に近い?
大域的コントラスト強調より、局所的にやるほうが計算量が大変。
まじめにやるとループが出てきてしまってパイプラインにならないので、違うやり方を考えた。直前の計算結果をフィードバックするところがポイント。
9bit x 256階調のヒストグラムをレジスタで並列に持っており、1clk/pixel で処理できる。
ウインドウサイズは 60×60 とか、もっと大きいのとか。あんまり小さいとノイズだらけになる。
かなり速くて 500fps くらい出るので、256 階調一気にやるのではなくて、たとえば半分の回路で128階調ずつとかにしてもいい。メモリが問題なんだけど、分割をうまくすれば意外とうまく使えそう?
[動的再構成プロセッサアレイMuCCRA-3のマルチコア化の研究]
DRPA を単に大きくするのじゃなくて、小さいアレイをたくさんならべるマルチコア化。
入出力のバッファはダブルバッファになってるんだが、入出力バッファ群とMuCCRA-Core群をクロスバを介してつないで、ぱかぱか切り替えられる。
泉先生: コアがふえたらクロスバでは大変じゃない?
さっさー: 接続は10数個くらいを考えているので、クロスバでもいいかな。
梶原さん: 各タスクに分けたときに、それぞれのタスクは同期して動くの?処理と入力データによっては処理時間に伸び縮みをしたいと思う場合もあるかも。
さっさー: 長さが変わってもそこは同期が取れます。
谷川先生: PE数を多くする場合とマルチコア化、というのを最初に出していたけど、PE数を増やすほうがハッピーな場合というのはなにか考えられますか?
さっさー: ひとつのアプリケーションで性能を出したければ普通にPE数が多い方がいいわけなので、それはそれで。
[FeRAMを用いた不揮発リコンギャラブルロジックデバイスの試作]
Vdd が下がってきたら強誘電体メモリに書き込み、Vdd 復帰時に読み出す不揮発FFを開発。
VGLC アーキテクチャをこれで作って、island style なチップを作った。
不揮発FFの面積はD-FFの9.6倍・・・FeRAM はかっこいいけど難しい。
ふんがさん: コンフィギュレーションデータを FeRAM に書いたまま使えばいいんでは?
古賀さん: 実は FeRAM は破壊読み出しなので、FF に読み出さなければいけない。
名古屋先生: LUT でもよかったのでは?
古賀さん: コンフィギュレーションメモリのビットあたり面積が大きくなることはわかっていたので、少しでも面積を減らしたくて VGLC を使うといいかな、と思った。
[高精度な科学技術計算エンジン向けディジットシリアル浮動小数点演算器]
8倍精度以上の精度がほしいとき!あります!
でも、8倍精度 (256bit) の演算器は大きくて、並列度も低くて、いまいち。
digit serial にしたら、周波数や面積はどうなる? 最適な digit 幅は?
IEEE754だいたい準拠。非正規化数はアンダーフロー扱い、丸めは切り捨てだけ。
8bit 幅の演算器で、性能面積比で 1.3倍。
小栗先生: 割り算は下位からやるわけにいかないと思うんだけど、どうしますか?
谷川先生: 除算器を作らずに加算・乗算を組み合わせてやるしかないと考えています。
市川先生: パイプラインの段数の最適なポイントはビット幅によって変わるはずですが。
谷川先生: 動作周波数が同じになるくらいのポイントでやりました。
市川先生: パラレルをパイプライン化するのとディジットシリアルは実は本質的には同じなのでは??
谷川先生: いろいろ工夫すると実は同じなのかもしれません。ただ、バス幅を小さくできるところが違うかな、と思います。
弘中先生: 本質的には同じですが、根本的に違うのは、ピン数などの自由度が上がる点が大きく違います。
市川先生: Booth 木なんかを使う場合に、途中をすっ飛ばせる可能性もありますよね。
谷川先生: 長さが変わってしまうといろいろ難しいので、検討した結果固定にしました。
あー思い切ってこういうの使ってもいいのかもなー。
[SRAM型FPGA上の実装回路におけるソフトエラー耐性評価手法の一検討]
フレーム単位で部分再構成して擬似的にエラーを注入。
TMR 化しても完全にはエラーがなくならない。
天野先生: エラーが多くないですか?
木村さん: 別々に演算器を3つ作ったはずなんだけど、同じ回路だし、ツールがくっつけちゃったかもしれません。
泉先生: コントロール系が壊れて、全然動かなくなるようなことはなかった? すごい電流が流れて熱くなっちゃうとか。
木村さん+久我先生: 組み合わせ回路で、順序回路ではないので今回は問題ない感じでした。
名古屋先生: TMR なしでも、エラー注入回数より検出回数のほうが何桁か少ないのはなぜ?
木村さん+久我先生: 回路がすかすかなので、使ってないところを壊しちゃっているだけの可能性も。本当は、ちゃんとしたアプリケーションなんかを使ってやる必要があるかもしれません。
[FPGAにおける演算パイプライン共有化のためのデータパス分類手法の提案]
小川さんデビュー戦。
名古屋先生: LUT削減率ということでしたが、もともとの数はどれくらい?
小川さん: すみませんいまちょっとわかりません。
名古屋先生: 削減率とかはあんまり変わらないような感じですが、レイテンシに着目していいものを選べばいい?
佐野先生: 32個全部くっつけたら25%くらい減るの?
小川さん+柴田先生: 25%は積分とかコミコミです。
[布線論理の性能を引き出すストリーム処理]
– pipelined FFT
– FDTD: 誘電率の違いを使って電磁波で乳がんを発見できないか? (放射線でなくて)
— Markov chain + 逐次ベイズフィルタ
— Monte Carlo 近似 (粒子フィルタ): 条件付き分布を式によってではなく、多数のサンプル値(粒子)によって近似。まさにモンテカルロ。 → これ熱いんだよね!!
– 粒子フィルタで3D認識!
– MBE: Multi-band excitation speech model
— 最近のデジタル無線で使われている。位相を考えずに、各バンドのパワーだけを使う。非常にクリアに音声が送れるらしい
– 超高速メニーコアコンピューティング研究センター
— 超並列部門: GPU
— リアルタイム計算部門
SGMJ 2010: Day 3
[次世代シーケンサによる新規マラリア原虫ゲノムの解読]
– P.falciparum (熱帯熱マラリア)
– P.vivax (三日熱マラリア) 薬剤耐性のが出現。P.cynomolgi, P.knowlesi など、アジアサルマラリア原虫に近縁。肝臓休眠期があって治療が困難。未熟な赤血球に好んで寄生するため難培養。
– P.vivax ヒト
– P.knowlesi サル・ヒト 肝臓休眠期なし
– P.cynomolgi サル・ヒト (P.vivax にもっとも近縁)
P.cynomolgi を読んで3種間比較ゲノム解析を進めている。
454FLX と GAII と Fosid. P.vivax をリファレンスとしてアセンブル。真核なのでわりとしんどく、次世代シーケンサでの真核の新規ゲノム解読はおそらく日本初。
予想ゲノムサイズ 27Mbp で、現在 22Mb 。Scaffold 数は染色体と同じ 14 本になっている。
9割の遺伝子 (4649) は3種間で保存されている。
保存されてない遺伝子は 1298. そのうちアノテーとされているのは半分で、そのほとんどが多重遺伝子族。
赤血球進入関連遺伝子と宿主域との関係が興味深い。
[メタゲノム解析から見える下北半島沖地下生命圏生態系]
海底1000mくらいまで何カ所かでボーリングしている。1cm^3 あたり 10^6 〜 10^7 くらいの微生物がいる。
深度が深いサンプルほどとれる DNA 量は減少するが、rRNA の種類はあまりかわらない? 深いほど多様性が上がるのかも。
CO2 から Acetyl-CoA まで持っていく嫌気的な代謝回路とかが推定できた。
抗酸化システムも酸素を発生しない、嫌気的なパスウェイに関連する遺伝子が多数。
[イネ共生細菌の群衆構造解析]
イネ科とマメ科の共通性と相違性は?
植物はエンドファイト・エピファイト・根圏微生物を制御しているのではないか?
マメ科では根粒菌形成、菌根形成を制御する植物-微生物のシグナル伝達系があり、イネにもホモログが存在している。
イネの CSP 遺伝子型に依存する属がある (劣性ホモだと菌が増えない)。
エンドファイトや根圏微生物の細胞をうまく濃縮してとってくる方法を開発。濃縮した場合とそうでない場合で出てくるグループがちょっと違う。これは、土壌に強く attach しているやつなんかが土壌と一緒に落ちるからではないか、とのこと。つまり、scope は違うけど両方正しいのかな。
rRNA と nifH (nitrogenase: 窒素固定遺伝子) でグルーピング。
根まで入れると大変なので地上部のメタゲノム。
[高温発酵コンポスト及び原料汚泥の最近群衆構造解析]
下水汚泥の余剰分をコンポスト化する方法がとられはじめている。高温堆肥化法 (80度以上で発酵させる!)。高度好熱菌の関与がありそう。
高分子汚泥、消化汚泥、石灰処理汚泥では嫌気性の菌が多いが、コンポストでは好気性のが多いので、高温発酵のところで大きく変わるのかも。ただし、出てきたのは中等度好熱菌で、高度好熱菌は見つからなかったが、これは実験の sensitivity が低いからか、あるいは分類が悪くて実際には中等度ではなく高度好熱菌なのかも。
[大腸菌多重遺伝子欠損株の解析によって明らかになった中心炭素代謝の新経路]
中心炭素代謝回路の70遺伝子中、必須なのは (glucose が炭素源の場合) 4遺伝子だけ。
バイパスがいろいろありそう。wet 実験と同じことを計算機シミュレーションでも実施。
ふむむ。dry のほうはそこまでモデリングできるものかな?
[半定量的発現プロテオミクスによる芳香族分解の代謝経路解析]
ラベルフリー法、というのでタンパク質定量 (MS/MS スペクトルの数を使う) を行い、サンプル間比較。emPAI という指数を使って、タンパク質混合物中にそれぞれのタンパク質がどのくらいの量で存在しているかを相対的に知ることができる半定量法。
Pseudomonas putida F1 を使用。5.96Mbp, 5250proteins. ベンゼン、トルエン、エチルベンゼンなどを分解できる。
どんな芳香族を入れるか・入れないかで発現が変わる様子を測定。ゲノム上のどこのタンパク質が出てるかを見られるのって面白いなー。
[トリコスタチンA処理の Aspergillus fumigatus におけるゲノムワイドヌクレオソームマップ解析]
TSA treated / untreated でヒストン脱アセチル化酵素に発現をみると、treat したほうがたくさん出ている。そのほかのヒストン関係の遺伝子もみてみた。
TSA treatment によってヒストンに巻き付く長さが増える。プロモータのところでは位置が重要で、ボディではそうでもない?
[大規模な逆位による染色体再編を利用した染色体機能領域の解析]
複製終了領域が細胞分裂時の染色体分配に非常に重要であることを発見!
複製開始点は両局に移動し、終了領域 (Ter domain) は細胞中央に局在するが、後者はただ引っ張られていると思われてきた。
変異株で Ter domain を分断すると染色体分配能が失われ、染色体を持たない無核の細胞が高頻度に生じる。
[非分化性の社会性アメーバAcytosteliumの遺伝子解析]
植物でも動物でも菌類でもありません。
概ね昨日お伺いしたとおりで、持っている遺伝子はだいたい同じだけど重複遺伝子の数が違うので、そのへんに注目しているよ、とのこと。
SGMJ 2010: Day 2
[高温・高圧の地下原油鉱床における固有微生物群とその特性]
秋田市八橋、新八橋油田。
– SR123 1687m, 98度, 113atm
– SR39 1100m, 74度, 29.2atm
のふたつの井戸から、地層水を含めてサンプルを直接採取。ここは海水注入とかそういうことはしていない井戸で、地表の取り出し口じゃなくてその地層のところから直接サンプルを採取している。
菌種の分布には違いがある。
高熱性の菌は GC-content が高いので、それを使って並べ替えると面白い。地表の取り出し口ではいろんな菌が増殖している。油井を掘るときに岩を削るのにたくさん水を流すので、そこでコンタミして、昔はいなかった連中がいる可能性もある。
重要なのは Bacteria と Archaea がうまくまじっているということ。酸素がない状況で Bacteria が有機物から水素を生成して Archaea がそこからメタンを作ることによる栄養共生。
[ランチョンセミナー]
Roche GS Junior
– Read length: 350bp
– Reads/run 100,000
– レーザープリンタと同じくらいのサイズで、机における。経済性を追求。
– 454 の 1/3 くらいの値段 (キャピラリーシークエンサと同じくらいの値段?)
– 2000万円あれば周辺機器も全部買えます。本体は1500万円くらいかな? コンピュータも付属
– 1 run の費用は10万円くらい
GS FLX Titanium 1k
– Read length: 1000bp
– Reads/run: 1,000,000
ガスケットで仕切るのと tag を使って分けるのとどっちがいい? → サンプルが少ないときはガスケット使った方が簡単。
[受賞記念講演]
真核生物の研究は酵母や動物細胞で行われており、植物では遅れている。
植物は倍数体が多いのでしんどいが、光合成をする真核微生物であれば、いろいろなことがわかる。
なるほどなー。
アブラムシの共生細菌からの水平転移遺伝子群。細胞内共生。
もう細菌は住んでいないけど、水平転移して残っている、というのがある。
共生とか寄生は面白いなあ (寄生されるのは、いやだけど)。
[マルカメムシ類の腸内に存在する必須共生細菌イシカワエラの比較ゲノム解析]
植物師管液を主たる栄養源とし、腸内に必須共生細菌イシカワエラをもつ。
ダイズでどれくらい繁殖できるか、というのが共生細菌で決まっている。
[Metagenomics-based 16S ribosomal RNA gene profiling]
454を使うので、chimera ができたり PCR bias がかかったりしない。
そうかー。うーん。やっぱり metagenomics って難しいんだなあ。
SGMJ 2010: Day 1
[比較ゲノム解析から発見されたグラム陰性細菌の新規タンパク分泌機構]
慢性歯周病の最重要細菌 Porphyromonas gingivalis.
偏性嫌気性、糖非発酵性、タンパク質分解酵素産生分泌、ヘム鉄要求性…
(つまり血液寒天培地で増やす)
II 型、III 型の分泌機構をもっていない!
この新しい分泌機構は2成分制御系で動いている。でもなんでだろ?
外部環境との関係とかがあるのかな、というお話。
[酢酸菌のゲノム易変異性の解析]
リケッチアとか根粒細菌と同じ Alpha-proteobacteria だけど独立して増殖できる。
ナタデココ (セルロース) を合成する奴もいる。
いろいろな carbon source を使っていろいろな二次代謝産物を作るのでよく使われるが、培養している間にどんどん形質がかわって、複数のコロニーを形成するようになることがある。
プラスミドが7つとか、たくさんある。それから、全遺伝子3000くらいで、そのうちトランスポゾンが300個くらい。10% 近いので、わりと多い方。Microsatellite, short tandem repeat がみられ、その長さで DNA polymerase III とか DNA helicase が変わってしまう。
90kbp とかの欠失が起きている株もあり、このグループの連中は genome reduction が起きやすいのかも?
大きな欠失があっても代謝系が壊れない (死なない) のでいろいろな mutant が見つかるのかも、というコメントも。
[転写開始点の塩基種に依存した枯草菌の緊縮転写制御ネットワークの解明]
アミノ酸飢餓状態とかでの転写制御系が、転写開始点の1文字目2文字目が A か G かで正の制御になるか負の制御になるかが違う。GC 含量ってそういうところにもきくのかな?なんか面白いね。
大腸菌と枯草菌では違う系だということだけど、他はどうなってる? → グラム陽性・陰性でずばっと分かれるのかも。
[新規情報学的手法によるインフルエンザAウイルスの俯瞰的可視化及び新型H1N1の変化予測]
BLSOM で、4塩基連続頻度をマップしてみると宿主別にきれいに分かれるよ、というお話。でも、新型H1N1はいままでの human のとは傾向が違って、avian のとの境界あたりにマップされる。これ使うと、いろんなインフルエンザウイルスのどれが次にヒトに感染しやすいか、みたいなのを計算できる。
Human flu は AT rich らしい。まじで?
[次世代シーケンサSOLiD3システムを用いた泡盛実用黒麹菌の比較ゲノム解析]
A. niger, A. awamori, A, saitoi など。
A. niger などの既報配列と比べたり。
GejiGeji: リファレンスと2試料について類似性を調べるツール (これ、read depth がずっと出るわけだけど、けっこう面白いな)。これを使ってみると、それぞれの麹菌株に特徴的な欠失領域があり、A. awamori と A. niger は大きく異なることがわかった。
欠失があるのはわかったが、特異的に多いところというのはわからない? →いまの解析方法だとわかんないです。
[バクテリアゲノムのリシーケンスによる変異解析とその問題点]
枯草菌168のリシーケンスのお話。枯草菌がみんなに配布されてから20年で、その間にいろいろ変異が溜まっておる。
maq (ungapped) と bwa (gapped) を使っている。
挿入・欠失など De novo のところは velvet + mummer を使っている。
いろいろなところの株を読んでみた。SNPは遺伝子の中に、indel は遺伝子間に多い。変異はいろいろあるが、どこでも同じようなところの変異が起きている。3rd letter の変異率が高い (42%)。ナンセンス変異は起きていない。
[多数株の種内比較によるゲノム進化ダイナミクス解析]
ピロリ菌日本株。
Mutagenesis, recombination, rearrangement で、とにかくゲノム進化が速い。
正確に読みたかったので Sangar 法で読んだ。
東アジア株はずいぶん遺伝的に遠いんだな。
1200の遺伝子について、RECOGを使ってマッピングしている。
東アジア株で特異的に喪われている遺伝子が5、特異的に存在する遺伝子が3。
東アジア株で特異的に重複が起きている、あるいは逆の遺伝子もある。などなど。
Mauve で rearrengement を計算している。Mauve か・・・悲しい。
[大腸菌における複製と翻訳の遺伝的ネットワーク解析]
E.coli の網羅的一遺伝子ノックアウトライブラリ (Keio collection) を使ってる。
科研費ゲノム特定成果公開シンポ: Day 2
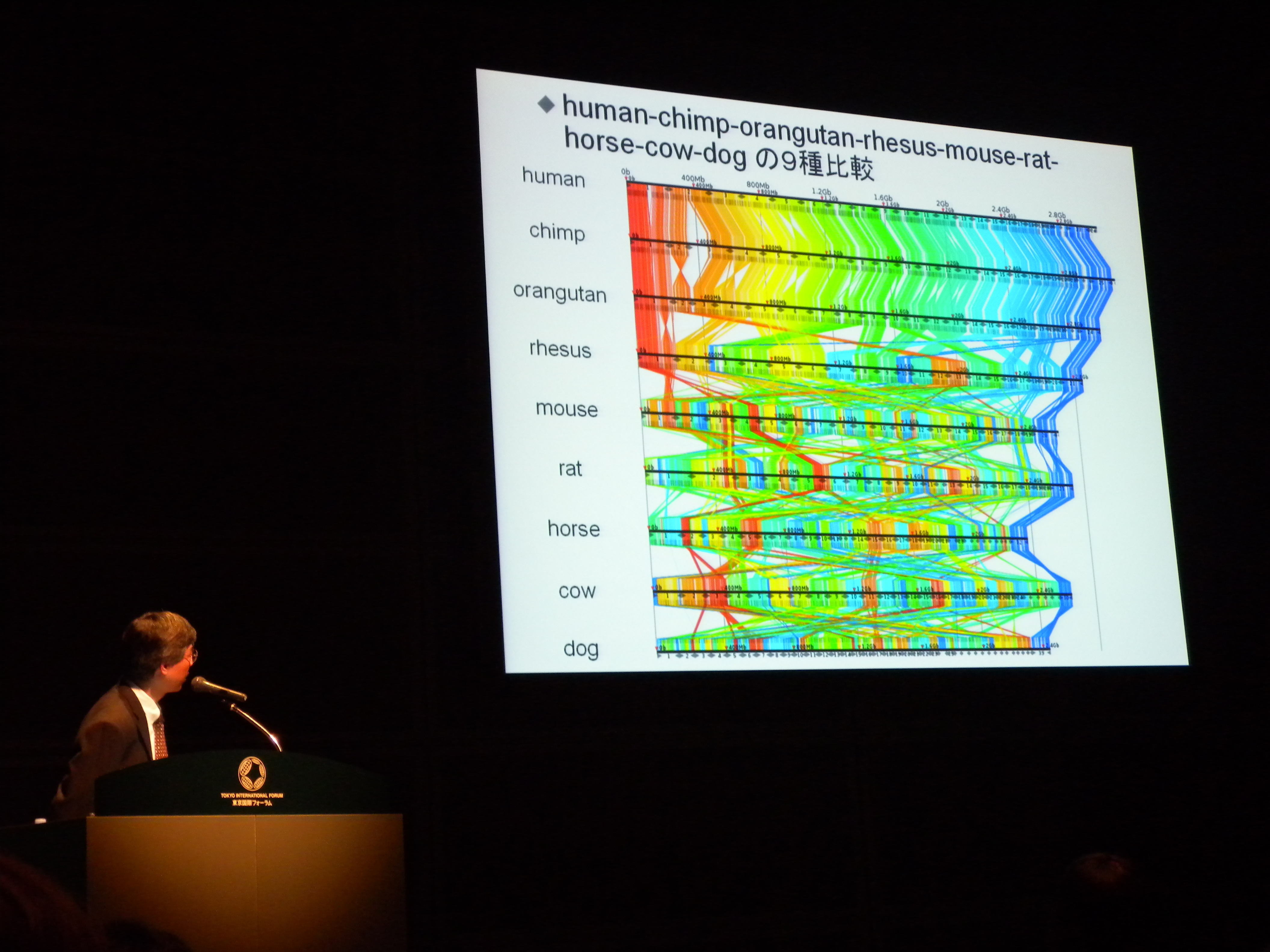
[ DNA はどのように折りたたまれているのか? ]
森下先生@東大。
源氏物語: 原本は存在しなくて、写本がたくさんあり、それぞれ巻数が違ったり indel とかがある → ゲノムの染色体の本数とか配列の違いに似ている?
ヒトのゲノムは 10 時間で複製される。50塩基/秒で、100並列。
祖先ゲノムがどうだったか、ということを知るのに、ヒト・チンパンジーとホヤ・ナメクジウオだけではなくて真ん中の魚類くらいのが必要だった。
脊椎動物の祖先ゲノムは10本くらいの染色体があったのではないかと推定しており、ヒトに至るには2度のゲノム重複が起きている。魚類はさらにもう一度。
染色体が物語の一巻だとしたら、ページに対応するのがヌクレオソーム構造。
プロモーター結合がページを開くことに、メチル化がページを閉じることに例えられる。
(染色体をコピーするときはヒストンに巻きついた状態で複製され、体細胞の分裂の際にはメチル化の情報も伝わっているっぽい、のだそうです。)
メダカ+Solexa で調べてみた結果、ヌクレオソーム構造を取っているところとそうでないところで、塩基置換率が違う (ヌクレオソーム構造を取っているところでは、ヌクレオソーム構造を保存する方向に塩基置換が起きている。10年くらい前の酵母の研究では、ヌクレオソーム構造の中心ではリンカーの部分に比べて修復率が落ちているので、そっちが問題なのかも) ことがわかった。おもしろいな。
コンピュータはだいたい 2x in 18month なのが、sequencer は 2x in 8month なのでやばいね、というお話も。そうなんです…
Solexa は 1bp/h くらいで超並列だけど、Pacific bio のは 4bp/s くらい。ただ、後者は並列化が課題みたい。
中国はすごい勢いで Solexa GA とかを購入して頑張っているそうだ (台数としては、日本全体とあんまりかわらないけど、日本は分散しているのが問題かな。)。うおー。がんばらないとなあ。
[ Wiki によるデータベースと研究成果の発信 ]
有田先生@東大。
計測と解析は速くなった。でもその真ん中にある整理 (curation) は?
科学は知識の積み上げだから、成果が再利用されないと意味がない。でも、論文も学会発表も報道発表も、再利用には向いていない。
我々はデータ中心という新しいパラダイムに直面している。一般人は科学を信じ、期待しているのに、科学者は一般人に理解してもらうことを放棄。科学者がデータ中心の概念に対応できていないのは問題で、いつまで雑誌崇拝がつづくのか?
subscription fee が上がっている背景には、投資ファンドが雑誌の出資元を持っていることも影響している。
有田先生 Wiki はすでにいくつかの学会の公式なデータベースとして認定していただいているそうで、成果公開というのは大変重要なプロセスにおけるこういう活動は非常に重要だと思う。
数式とか理論的なものはいいけど、ゲノムとかそういう大規模なデータはどうやったらいいと思いますか (森下先生) → Wiki は backend が RDB なので、なにかそういうものを考え直さないといけない。いずれにしても Web ベースでやれる仕掛けは必要。
[ 多生物種のゲノムを高速に比較する並列システムの開発 ]
榊原先生@慶應大。
質疑だけメモ。
– マウス・ラットでは再編成が起こりやすい系統があるようですがそういうのと比べてみると面白いかもしれません。
– X染色体はヒトとチンパンジーでかなり保存されているがY染色体はシャッフルされている、という話がでているけれど、どうでしょう。 → Y のほうはまだアセンブリがきれいに進んでいない生物が多いので比較ができないのが現状です。
– NIG とか UCSC で visualize できなくて Murasaki & GMV でできるものは? 入力フォーマットは一般的なもの? → お答えしておきました。まさか回答させられるとは・・・
科研費ゲノム特定成果公開シンポ: Day 1
午後から参加。微妙に遅刻したところを U 先生に見つかってしまいました。えへへ。
廊下で立ち話して、最近の進捗をお伺いする。お手伝いできることがありそうなのでがんばります。
[ 土壌での微生物の生き様をゲノムから見る ]
津田先生@東北大。
土壌汚染物質を添加して、時系列でメタゲノム。菌叢が大きく変わるの、面白いな−。
しかし、メタゲノムやると、16s rRNA は 99% データベースに当たらない暗黒な世界なのだそうで、それはどうやったら解決できるのかね?
[ 麹菌のゲノム情報を活用した有用タンパク質の高生産 ]
五味先生@東北大。
「もやしもん」で微生物に興味を持つ高校生が多いのかー。
洗剤のアルカリ・リパーゼは麹菌の組み替え株で大量生産しているのだそうな。
固体培養 (麹培養) と液体培養では全然生産性が違う。低水分ストレスとかが効いてるのかな。
いろんな転写因子を網羅的に高発現させてみた。
麹菌に遺伝子導入をして工業的に使う、というのは既にいろいろやられているのだけれど、麹菌はプロテアーゼとかペプチダーゼを大量に作る (しかもものすごい種類を持っている!) ので、遺伝子導入してもせっかく作ったタンパク質を壊してしまう。
タンパク質分解酵素に関連する転写因子をみつけてそれを破壊してみたところ、多くのプロテアーゼの活性を抑えることができ、収量が改善した。
[ 病原性大腸菌の比較ゲノム解析とその応用 ]
林先生。
O157 ではふたつの IS (IS629, ISEc8) が飛び回っており、ファージのところに頻繁に入っている。
2回のPCRでO157であるかと、どの株であるかを特定することができるプライマーセットを作った。これは、集団感染であるかどうかを診断するために非常に有用で、制限酵素+パルスフィールドよりずっと速く、簡単。TOYOBOでキット化しており、診断に使われている。
日本では O157 >> O26 > O111 だけど Non-O157 の割合が増えてきている。欧州などではO157 の割合は比較的少なく O121 > O91 > O103 > O128 > …
O26, O111, O103 の配列を決定したが、ゲノムワイド系統解析では O157 とはまったく別になるものの、遺伝子クラスタに基づく解析だと EHEC は同じグループになり、並行進化していることがわかった。
Non-O157 EHEC のラムダ型ファージも、O157同様に III 型分泌器をもっていたり、プラスミドが同じような病原遺伝子セットをコードしている。でも、プラスミド間で相同性があるのは病原遺伝子の領域だけで、もともと同じプラスミドを獲得してきたわけではなさそう。
O157 とウシとの関わりはこれからやらないといけない。直腸の出口あたりにかなりの長期間定住しており、ウシでは病気は引き起こさない。一種の常在細菌といえるかも。
[ メダカの研究から発生、進化、病気のメカニズムを理解する ]
武田先生@東大。
メダカの内臓逆位個体では繊毛のモータータンパク質の欠失による腎臓病 (多発性嚢胞腎) や精子の運動性低下が起きる。ヒトでも繊毛の運動性低下が原因の遺伝性疾患があるが、同じ遺伝子の塩基多型が原因で発生することがわかった。
背腹の形成に異常がある変異体 (お腹も背中も丸くて銀色で、背びれと腹びれが同じ大きさ) もある。これの原因領域には2つの遺伝子があるだけだが、これらのコード領域は同じ。しかし、変異体では転写制御領域に変異があって発言パターンが異常になっていた。
メダカはいろいろな変異体が愛好家によって飼われていて、ゲノムも一倍体なのでいい感じ。金魚は四倍体?
[ 立襟鞭毛虫のゲノム情報から動物の多細胞化を探る ]
岩部先生@京大。
Monosiga ovata. 淡水性。64Mbp. 2万遺伝子。
海水性のは 42Mbp で、9000遺伝子くらい。
チロシンキナーゼは動物特異的だと思われてきたが、立襟鞭毛虫でも見つかっており、分子進化系統樹を書くと面白い。ほかにも動物特異的に多様化したと考えられていたシグナル伝達分子があり、それらは今後の課題。
イソギンチャク (刺胞動物): 神経系あり。
センモウヒラムシ (板状動物): 細胞が4〜5種類。神経系がない。
とかの微妙なところを含めて比較ゲノム解析してみた。
これすごいなー。
カドヘリンは僕らは細胞接着に使うけど、立襟鞭毛虫も持っている。襟のあたりでエサを捕まえるとか、なにか違うことに使っているのかも?
[ マウス亜種間ゲノム分化を利用した複合形質の遺伝解剖 ]
城石先生@遺伝研。
Mus musculus は地域ごとにいろんな亜種がある (北米には元々いなかった!)。
世の中で使われている実験系統 (C57BL/6J) は西ヨーロッパ産亜種。
遺伝研では三島でつかまえたマウスから日本産亜種の系統 (MSM/Ms: MSM=MiShiMa) を確立。 亜種間の塩基置換率は 0.87% くらい。
MSM/Ms はキャピラリーで 2.4x, Solexa で 15x で読んで貼り付けて、99% coverage. 11,742,976 SNPs. うち、Non-synon. SNPs (アミノ産置換あり) が 26.000. Non-sense mutations は 131 遺伝子で見つかった (0.5%!)。
MSM/Ms は体のサイズが約半分、発がん抵抗性が高い、エネルギー代謝系が節約型、など、表現形のレベルでいろいろな違いがある。
亜種間交配によって特定の染色体だけが別の亜種由来なもの (コンソミック系統) をすべての染色体について作った。
多くの量的形質については、単に足し算と引き算だけで成り立つ (全部足したら100%になる) のではなく、全部足すと100よりずっと大きくなる (遺伝的交互作用=epistatsis が強い) ことがわかった。