久しぶりに自転車乗った。しかも八ヶ岳南麓。
身体が完全に坂の乗り方を忘れており、えらく苦戦した。
県道17号に、新しい橋が開通しており、非常に気持ちいい。以前はこの下の道を下って上がって、そりゃもう大変だったのだよ。橋の上からの眺めもよかった。しかも、逆方向だと、正面に富士山が見えるんだ。

31.04km @ 24.2km/h (1h16m42s) odo 3100.7km
月: 2007年5月
金沢行ってきた
そういうわけで、先に研究会メモを載せちゃったのだが、金沢行ってきた。
残念ながら旅費が出ないので、コストダウンを図って、
– 往路は急行「能登」で、上野ー長岡ー金沢
– 復路は普通列車で、金沢ー糸魚川ー松本ー高尾
という予定を立てた。これだと、往路が9000円ちょっと、復路が7000円弱で、宿代が4000円弱なので、2万円に収まる計算だ。わお。
「能登」は、当然ながら寝台列車ではないが、むかしの特急列車の車両 (489系) を使っており、なかなかよかった。決して新幹線みたいに快適ではないけれど、ボックスシートを占拠して横になってしまえば、なかなかのものだ。普通列車のボックスシートより座面が長いのか、いつもの中央線普通列車より断然快適。

高崎まではうとうとしていて、高崎を出て、八木原くらいから記憶がない。目が覚めたら富山あたりで、強風のため遅れている、とのこと。ありがたく眠らせていただいて、35分遅れくらいの、7時10分ごろ到着。駅構内のパン屋さんで朝食。激うま。
金沢は天気が不安定で、ときどき嵐みたいに降ったり吹いたりだったのだが、そういうのは僕がスターバックスで書類と戦っていたりとか、会場に着いてぼーっとしていたりとか、そんな時に限られており、その合間を衝く形で武家屋敷の町並みだとか、金沢城址なんかをみてきた。全般的に、非常に文化的な感じの街で、非常によい。そういえば駅の建物も、なんかすげえカッコイイんですよ。

写真は金沢城の、五十間長屋。で、城の近くのラーメン屋で、鍋焼きラーメンとカレーのセット、というのを頼んだ。猛烈にお腹がすいてたしね。しかし、ラーメンは普通にゆでてました。残念。

午後は発表で、夜は懇親会で、その晩はホテル。
布団で寝られるって素晴らしい。寝坊したけど。
翌日も午前中は、若干寝坊して後輩二人の発表を聞き損なったものの、お昼まで研究会。
終わってから駅へ行ったら、もう普通列車では帰れない時間だったので、糸魚川まで特急に乗る。特急券が1200円くらい。糸魚川の手前、親不知のあたりは線路が海岸を通っており、いい景色だった。



糸魚川から大糸線。南小谷まではディーゼルだ。キハ52というやつで、糸魚川の駅に停めてある3両で国鉄時代のディーゼルカーの3種類の塗装が揃っており、JR西日本、なかなかやるな!という感じ。キハ52は、かなり昔の車両なわけで、懐かしい感じでよかった。景色もいいしね。そういえば、窓際のテーブルの下には昔懐かしいセンヌキがついていた。これって、最近ないよね?


大糸線は久しぶりだ。南小谷からは電車。信濃大町で乗り継いで、松本へ。北アルプスの上の方はまだ、かなり雪が残っており、よい眺めだった。
松本で、車掌をしている後輩と会う。久しぶりにきたら、松本駅が変わっていて、びっくりだ。
松本から甲府行き、甲府から高尾行きに乗り継いで東京へ戻る。松本駅で、月見五目なんとかご飯、みたいなお弁当を買ったのだが、きのことか山菜とかがたくさん載っており、とてもおいしかった。松本に行ったら、また買おう。

ちなみに、写真はけっこう撮ったのだが、ほとんどフィルムで撮っていて、まだ現像してないので、そのうち載せる気になったら載せます。
RECONF2007 12-14 (May 18, 2007)
寝坊しました。まあ、最初の発表は身内なので許しておくれ。
[ PE 直結型動的リコンフィギャラブルプロセッサ MuCCRA-D の提案]
MuCCRA-1 の結合網は island style.
結合網は重要なファクタなので、直結型も作ってみることにした。
Nearest neighbor mesh ではあまりに柔軟性が低いので、ふつうはちょっと遠くへ行く線とかも引いておくが、いずれにしても直結。
IMEC の ADRES とか、日立の FE-GA は直結型。配線領域の面積コストや、隣接 PE 間の転送コストは安くなるが、データ移動の柔軟性が低い。
Nearest neighbor だけではなく、ひとつ飛ばしの配線もはいっている。
配線がレジスタなので、載ってしまえば 166MHz とか出て速い!
並列計算機に似ていて、メモリにどうやってデータをマッピングするかで大きく性能が変わったりする? (井口先生)
→ そう。MuCCRA-1 では、競合さえ起きなければ問題ないが、MuCCRA-D ではどこに置くかが大きな問題になってしまう。
プログラミングは手動? つまり、手作業で並列化プログラミングしているようなもの?
→ 配線も含めて手動です。MuCCRA Editor で配線。
デッドロックしませんか (堀口先生)
→ turn model を使って、禁止ターンをする場合とか、下方向への転送をする場合にはレジスタを通さないといけなくなる。
MuCCRA-D も大きくなったら、レジスタを増やしてやれば VC が作れる?
→ そういうことも考えてます。
我々のと近い気がするんだけど、必要な計算結果が違うところで生成されちゃって困る、ということはないか。(弘中先生)
→ あると思います。コンパイラをまだ作ってないからアレですが。
アーキテクチャ的な対策は?
→ ひとつ飛ばしの配線が意外と効くんじゃないかなー。ダメなときはコンテキストを切り替えるとか…
電力的には? (梶原さん)
→ MuCCRA-D のほうが食う。同じ問題をとくのにかかるエネルギも、全 PE がフルスピードで動いちゃってるので、いまのところ -D がだいぶ不利。
[動的再構成可能プロセッサ Vulcan2 とそのソフトウェア開発環境 ISAcc に関する研究]
ASIP: application specific instruction-set processor を、動的再構成可能にする。
32bit RISC core に RDP (reconfigurable datapath) がついた構成。
ISAcc は C プログラムから、普通のコンパイルとあわせて命令セットの合成を行う。
64PE から 128PE になると急に効くのはなんで? 比較的小さいデータパスを使いそうだから、64 くらいあれば幸せになれそうなんだけど (梶原さん)
→ ISAcc が Vulcan-1 (128PEs) 用のコンパイラなので、他の configuration ではいまいちかも
命令ライブラリとパターンマッチングしてコードを作る、というところで、ライブラリが 128PE 用になってる感じ?
→ そうですね。ライブラリが充実すれば。
カスタム命令と通常命令の EXE ステージは並列実行できない?
→ いまのところそうなっているが、それも検討中。
Configuration data のロードは multicontext で、PE が持っているのか、それとも毎回配られるのか (ふんがさん)
→ まだ決まってません。Vulcan-1 では前者で、メモリが大きくなってしまったので、後者にしようと思ったが、遅延が隠蔽できなくなってしまった。
ALU じゃなくて LUT なのは?
→ ALU based なやつも検討に入ってます
[高速並列画像処理用再構成可能プロセッサエレメントの提案]
3D モデルを使った画像認識。いい環境条件ではそれなりにできるようになってきたが、条件に対してロバストではない。そこで、3D モデルをいろいろな条件でレンダリングしたものを大量につくって、それと 2D 画像を照合する方法を考える。レンダリングを高速かつ大量に行えば、うまくいきそう?
RECONF2007: 1-9 (May.17, 2007)
[ 通信状態に基づくパケット毎自己再構成を用いた動的再構成プロセッサ搭載クエリトランザクション高速化装置]
日立中研の磯部さん。
データベースなどのネットワークアプリケーションで、クライアントとサーバの間 (ルータの中とか) に置いて高速化を実現するような appliance。たとえば、キャッシュをしたりとか、データベースへの挿入要求をいくつかまとめてからサーバに送ったりするようだ。さまざまなサービスに対応できる柔軟性と同時に、ルータなどに内蔵するために小型省電力であることが求められる。
通信データをメモリにバッファすると、ネットワークコントローラとプロセッサが同時にそこにアクセスするので帯域幅がもったいない → プロセッサに直結したい。
すべてのパケットがすべてのプロセッサを通過するのではなく、たとえば簡単なパケットは最初のプロセッサだけで (浅いパイプラインで) 処理を行い、複雑な処理が必要なものは複数のチップを使って処理能力を稼ぐ。
通信相手ごとに、いまなんの処理を要求されているかを把握しておき、どの回路を使うかを切り替える。構成情報は on-chip のキャッシュにあったり、外部の DRAM に置いてあったり。
TCP とかそのうえの HTTP とか SQL query を実装してみた。DDoS 対策にもなって、しかも本当に速くなるんだぜ!
チップは DAP/DNA-2 らしい。
キャッシュが当たれば 1 クロックで再構成、外れれば 10k clks. そのへんはどうなんでしょう? (泉先生)
当たり続ければ wire rate で処理できるが、外れはじめるとがくっと性能が落ちてしまう。入り口で順番を並べ替えてやればいいかもしれないが、それはそれで大変。
これ、サーバ系とはいえ、ストリーミングなので、データベース自体をやろうとしたら大変? (泉先生)
それはとても大変だと思う。
RISC core が載っているが、それは使ってない? (柴田先生)
使っていません。メモリの競合もあるので、使った方がいいか悪いか…
入力バッファを見て投機的にキャッシュに入れていくのはどう? (NEC 梶原さん)
そうですね。やりたいです。
[レーベンシュタイン距離を用いたテンプレートマッチングアルゴリズムのFPGA実装]
ふんが研の清水くん。
いま実装されているやりかたでは位置ずれに弱いので、レーベンシュタイン距離 (つまり edit distance) を導入。これは挿入・削除を許すので、位置ずれを許容することができるが、計算がしんどいので、ハードウェアで頑張って高速化する。
HSV に変換して色を検出。なるほどー。
色の境界線を 0度、45度、90度、135度の4種類の接線に近似して、この4つにそれぞれ文字を割り当てることで、画像を文字列化する (how cool!)。
Bach-C で書いた。Handel-C と違って、タイミングの制御はコンパイラがやってくれる。まじかよ。
水平・垂直の距離計算は並列にやる。で、そのセットを4つ並べて x8 。
FPGA で、2.8GHz Xeon の 4.8 倍くらい。
DP のテーブルはメモリに全部持ってしまっている? (おさな)
32×32 だからまあいいか、ということで入れてしまっている。
標識が回転しちゃっていることとか、文字の大きさがどうかとかあると思いますが (泉先生)
大きさに関してはある程度 tolerant であることを確認した。回転はこれから検証。
赤・青の検出のエラーレートはどれくらい? テンプレートの数は? (廣田先生? @ 九大)
色の識別は自分の実装でないのでノーコメントです。
いまは大分類の (赤い丸とか青い四角とか三角とか) しかないので、たいした数ではない。大分類したあとで小分類のを作っていかなければならない。評価にレーベンシュタイン距離を使っているので、計算量はテンプレートの数にリニアに比例するだけで済む。
[生化学シミュレータReCSiPにおける反応速度式共有化]
山田さん。
スライドがかっこいいぜ兄貴。
Solver Core は共有化しても 100MHz を確実に越えられる感じ。単体のときよりは若干複雑になるので、まあ、数 % は落ちるが。スライス数はだいたい 35% くらい減る。わお。
スループットが 14% くらい落ちてる。これはパイプラインピッチが長い方に揃ってしまうのが問題で、やっぱり入出力のところをなんとかしないといけないな。
グラフの同型判定はとても大変 (NP) だけど? (飯田先生)
まだ小さいので、exact に最適解が求まっている。
ずっと演算器が忙しい、というのが前提だと思うんですが、暇なのもあるんですか? (森先生)
システムがいろいろな式を含んでいるので、multifunction なモジュールを作ってやらないと面積が無駄になってしまう。
連立する式のセットを眺めたときに算数のレベルで簡単にできることとかありそうだよね (森先生)
ええと・・・方法があったら教えてください → 私もわかりません(笑)。reconfiguration と、共通部分式の抽出を組み合わせたりすると面白くなりそうですね。
木のマッチングはNPじゃなかったかも。でも、加算みたいな、左右が可換な演算はどう? (泉先生)
まだ考えていません。とてもむずかしい。
稼働率で評価しないといけないのでは? (飯田先生)
それはいまやってます… 半年くらいお待ちください m(__)m
[リコンフィギャラブルマシン SRC-6 を用いた海洋モデルシミュレーションの実装方法]
POP: Parallel Ocean Program
3次元球体上で流体基礎方程式を解く、気象予測とかの標準。
けっこう速いのだが、DMA が時間を食ってしまって Xeon に負ける場合がある。配列をうまく切り出したり、ブロックサイズを適切に選ぶことで FPGA が有利になる。
精度は single? double? (井口先生 @ jaist)
double です。64bit です。
わお。
ソフトウェアでも、ブロックサイズでずいぶん違うんだけど、やっていることは同じ? DMA の速度はどれくらい出ている? (井口先生)
演算量も workset サイズも一緒なんだけど、グラフに出ているのは関数1回あたりの時間なので。
DMA について、図 9 で送っているデータは 256KB で、300us だから 1GB/sec くらい。バンド幅としては悪くないですね。
いろいろ改良しても、やっぱり DMA が律速だと思うんですが (泉先生)
メモリインタリーブをするとコンパイラが別の配列として認識しちゃう。
オンボードメモリにデータをどう配置するかが問題ですだ。
[チップ間無線通信を用いた3次元動的リコンフィギャラブルデバイス MuCCRA-Cubeの提案]
天野研の斉藤君。無線方式 (誘導結合なのでベースバンド信号だ) での積層チップ。
MuCCRA-1 がベース。MuCCRA-1 は、PE 間結合網が island style.
RoMultiC 入ってます.
チップを重ねるときに、同じ向きで重ねるのでなくて、違う向きで重ねてやると配線長を短く使うことができるのではないか!?
重ねたチップを同一コンテキスト番号で駆動するか、個別に駆動するか。後者はパイプラインみたいにして使えそうだ。
MuCCRA-Cube は各 PE がインダクタをもっており、それで双方向通信する。コンフィギュレーションデータも、一番下の段から入って、無線で転送される。そのへんの面積オーバーヘッドは 10% くらいで済む。
でも、評価してみたら、あんまり配線長に効いてこないので、全部の PE にインダクタをもつ必要はないかも。
3次元方向に飛ばす場合に、どこまで飛ばす? 気合い入れすぎると相互に干渉したりしない? (泉先生)
基本的に隣接する、上下のプレーンに飛ばすことしか考えていない。
縦方向のほうが通信コストが高くなるから、同一コンテキストで動かすような密な関係じゃないほうがいいかもしれませんね (泉先生)
Multicore な感じとして捉えれば、同一平面の遠くの別のコアよりも、上下のプレーンの別のコアのほうが近い。
誘導の漏れを使って、隣と通信するようなことは考えてない? インダクタを switch matrix ではなく PE に持たせたのはなにか理由が? (森先生)
PE 間で接続したほうが、アプリケーションの実装が簡単になりそう。
電力削減って、どこのが減りそう? (堀口先生)
配線の電力が減りそうです。
インダクタによる通信のレイテンシは? (名古屋先生)
1GHz で通信して 1クロック = 1ns とかで OK.
[動的再構成型ハードウェアの階層型状態切り替え方式]
堀口先生。
PE 使用率がだいたい一定になるようにうまく均してやると消費電力が安定したり、削減できたりするのではないか、というのが motivation. 電力モデルを作ったり。
いろいろ調べていくと、idle な PE が意外と電力を食っていた! DRP はタイル単位でしか止められないので、状態遷移を細かい粒度でやるなら階層的な状態制御コントローラが必要で、もちろんそのぶんハードウェアコストが高くなるけど、いい感じだ。動作電圧なんかも制御できるようにするとより効果的、というか、リーク電流の割合が増えれば増えるほど、それは必須の処理になる。
いまの構成だと、PE を全部使えるほど配線がないので、このまま PE を増やすよりも、配線可能性を高めたりするほうが電力的にはよくなる? (柴田さん)
64PE 単位だとやっぱり粗すぎるかもね。
再構成をしないほうが電力効率がいい、という結果が出てましたよね (弘中先生)
メモリとのデータ転送なんかもあるので、プローブを当てて測っているわけではなくて、DRP compiler が出しているのでなんとも。しかし、コンテキストをまとめた場合にどうなるか、という実験 (もちろん推測なわけだが) の結果からパラメータを導出することができなかった。
DRP は複雑だが、もっと簡単なモデルで再構成したほうが電力的に得だ、ということはあるんでしょうか? (弘中先生)
そうなるといいな、と思っていたんですが、うまくいかなかった。
速度最適、とか、電力最低、というのはあるのだが、1W あたりどのくらい、という効率の計算にしようとしたら、難しい。
[粒度可変構造論理セル向け算術演算回路の実現]
佐藤さん @ 熊本大
Hybrid cell: FA + 4bit FF = 2-LUT.
これに front logic というのをつけて、Add/sub, 2-LUT, 2-MUX として使えるようになっている。さらに、制御信号線を入力として、3-NAND, 3-AND, 3-EXOR ができる (3-OR, 3-XOR はダメ)。4 入力もできるけど、3 入力より poor.
で、これを使った各種の算術演算器を作成。
Carry Select Adder とか Parallel Prefix Adder とかも作っててかっこいい。
logic だけで interconnect が入っていないけど、アレイ型でtree いれたらやばいとか、なにか考えていることはありますか? (泉先生)
→キャリーチェーンをなるべく使いたい。
結局 RCA がよかったりする、と思うんだけど、Wallace はどう?
→キャリーチェーンはうまく使えなかった…
粒度固定の、一般的なロジックセルの場合と違う結果になったりしました (柴田先生)
→Carry Lookahead はうまくいかなかった。
最近は embedded multiplier がはやりですが
→できれば均一な構成にしたい
[スモールワールドネットワーク化配線構造の詳細遅延評価]
西岡さん @ 熊本大
short から long まで、4段階の長さの配線を持つ island-style FPGA に SWN を加える。
E 本の配線 (edge) があるときに、確率 p で pE 本の SWN wire を追加。かわりに long line を削除する (プロセスが微細化するほど long line の使用率は低下)。
VPR の PathFinder アルゴリズムをベースにして配線アルゴリズムを実装。
1. すべてのネットに対してコストが最小になる配線経路を探索
2. 競合する配線にはコストを加算
3. goto 1
SWN ラインがあると、マンハッタン距離=最短距離とは限らなくなるので、そこの変更が必要。なるほどー。
評価は、SWN 生成確率をかえて、それぞれで 5 パターンの配置を試した。MCNC benchmark.
配線に時間がかかるって、どれくらい? (井口先生 @ jaist)
→1% の場合と 2% の場合で単純に 2 倍。SWN wire の数に線形比例。
基本的に long line のかわり? p はどれくらいにするのがよさそう? (産総研の方)
→そうですね。p のほうはまだ一概には言えない感じ。
ランダムに斜め線があるのと、規則的に斜め線があるのでは、ランダムであったほうがよいという感触はある? (森先生)
→規則的にやったほうが、遅延は削減しやすいと思うが、リソースを食い過ぎる可能性があるので、ランダムのほうがいいかなー、と思っている。
→ランダム性を持ち込んだ時点であちこちで悪さが出てくるので、もしかしたら規則的にするほうが、製造プロセスや CAD の都合もあって、そっちのほうがいい、ということもあると思う。
[SoC埋め込み型プログラマブルロジックePLX向け自動配線ツールの検討]
立命館の奥野さん。
SoC にプログラマブルロジックを埋め込むことで、少量生産品にも使えるような SoC の開発を狙う。
LUT, FF, Interconnect block が交互に並んだカラム型の構成で、こいつの配置配線手法。
Dijkstra のアルゴリズムを使って、個々の net を配線する基本ルータを作って、それを繰り返すことですべての net を配線していく。なので、配線をする順番次第で性能が左右されちゃうのだが、それは今後の課題みたい。
interconnect は階層構造みたいだ。
ePLX はアーキテクチャを絞って、配線を減らしているから SoC に適している、と考えてよい? (梶原さん)
→ ルネサスさんといっしょにやっている。フィルタ用とかプロセッサは持っているので、プロセッサでも信号処理でもない、ノリスケロジック (って、glue logic みたいなものだな)。
LUT matrix はどうつながってる? (弘中先生)
→ ひとつからは 13 箇所に直接つながっている。
なんで 2-LUT? それじゃゲート一つじゃない? (飯田先生)
→ 最初は LUT ではなくて NAND + Inverter の海だった。LUT ひとつでロジックブロックなのではなくて、ぜんぶで一つの LB みたいな感じ。
そうすると LUT 間の接続の議論もありますよね? クラスタリングとか。
→ それもまた議論しています。いまの構成で OK 、という結論がでているわけではない。
恋しぐれ
全然浮いた話じゃないですが。
恋しぐれというイネの品種が最近開発されたのだそうで、コシヒカリといくつかの品種がベース。遺伝子操作を直接やったというわけではなくて、背が高くて倒れやすいけどおいしいコシヒカリと、おいしくないけど背が低くて倒れにくいいくつかの品種の遺伝子マーカーを徹底的に調べて、うまく交配したんだそうだ。
育種っていうのは本来、何十年もかかる作業だそうなのだけれど、ゲノムが読めると簡単にできる、というのが楽しいね。
Grand Depart: TOJ
欧州じゃ Giro が盛り上がってるようですが、日本でも Tour of Japan がはじまりますよ!
今年は信州まで見に行くぜ!
RDT Illustrated
修士の時に、国際会議に行った先で、POV-Ray を使って作った RDT (Recursive Diagonal Torus: JUMP-1 の結合網) の図。横から見たイメージと、上から見たイメージがあります。
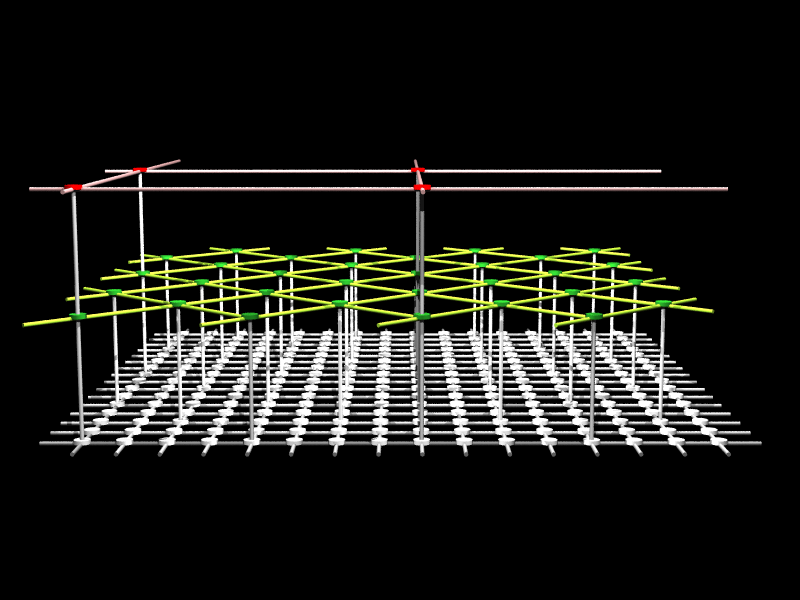
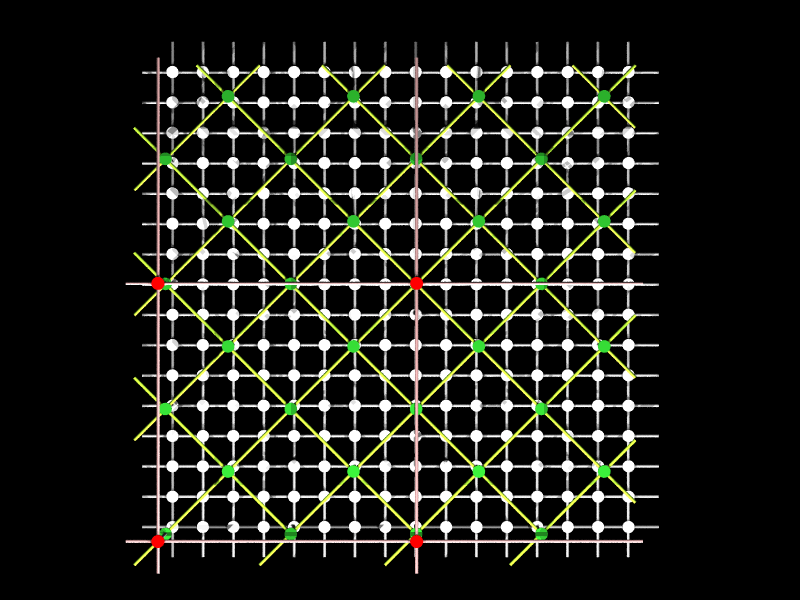
階層的にマルチキャストをする様子を説明するために、1段ごとにレンダリングしたものなどを用意して使いました。ソースファイルもまだ残っていますので、必要な方はお問い合わせください。
JUMP-1 @ Amano Lab.

天野研の JUMP-1 のシステム。雑然としていますが、手前が 16PE の本体で、後がわに電源ユニットが置かれています。電源の上に 3 台積み重ねてあるのは STAFF-Link のホストになる SPARCstation5 で、上に置いてある透明の箱が STAFF-Link のマザーボードです。
MBP-light Chip Layout
鈴木さん (慶應大学天野研) のスライドから、MBP-light のレイアウトの画像もいただきました。

JUMP-1 demo @ PDC
PDC での JUMP-1 のデモの写真をいただいたので、掲載しておきます。
関係者のみなさまの肖像権に関してはお許しください…
























